- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Техника расчета 13 страница
5. Нажмите ОК. Результаты будут расположены в ячейках D2:F4, как показано на рис. 23.
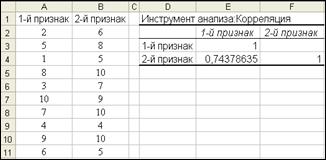
Рис.23. Двумерная корреляция
Результатом является матрица попарных корреляций. На диагонали расположены: цифра 1, показывающая, что каждая переменная положительно (полностью) коррелирована сама с собой; значение 0,74378635 -корреляция 1-го признака со 2-м признаком. Правая верхняя часть пустая, так как ее значения совпадают с соответствующими в левой нижней части. Если значение коэффициента корреляции выводится без знака, это означает, что корреляция положительная (прямая), если со знаком минус – отрицательная (обратная). В данном примере r = +0,74. Это указывает на положительную по направлению и среднюю по силе зависимость между двумя изучаемыми показателями, что подтверждает предварительный вывод, сделанный в предыдущем разделе. Но этот вывод не может быть окончательным, если не будет определена достоверность коэффициента корреляции. Для этого в ячейки D6 и D7 введите формулы, показанные на рис.24.
По введенным формулам будет рассчитано фактическое значение критерия достоверности коэффициента корреляции (tr) и число степеней свободы (df, в первой части пособия обозначалось как υ) (рис.25).
Определите по табл.17 значение критерия Стьюдента (tst) при 3-х уровнях доверительной вероятности. В данном случае (tst) = 2,3-3,3-4,8 (при P=0,95-0,99-0,999). Получается, что td = 3,15 > tst (при P≥0,95), что указывает на достоверность коэффициента корреляции и правильность сделанного ранее вывода.
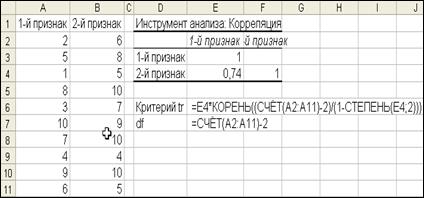
Рис.24. Формулы для расчета критерия достоверности коэффициента корреляции
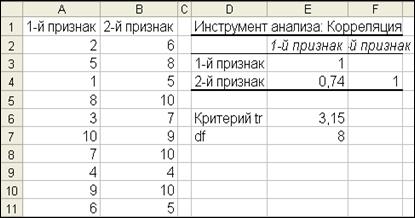
Рис. 25. Результаты расчета критерия достоверности
КОРРЕЛЯЦИИ НЕСКОЛЬКИХ ПЕРЕМЕННЫХ
Инструмент анализа Корреляция наиболее полезен при определении попарных корреляций трех и более переменных для последующего использования в множественной регрессионной модели. Следующие инструкции описывают вычисление корреляции нескольких переменных.
Пример 2. Имеются следующие данные по удоям коров, с содержанием в молоке жира и белка:
| Корова | Суточный удой, кг | Жир, % | Белок, % |
| 3,8 | 3,0 | ||
| 3,8 | 2,9 | ||
| 3,8 | 2,8 | ||
| 3,9 | 2,8 | ||
| 3,6 | 2,7 | ||
| 3,5 | 2,8 | ||
| 3,7 | 2,9 | ||
| 3,3 | 2,6 | ||
| 3,2 | 2,7 | ||
| 3,8 | 3,0 |
Порядок выполнения анализа следующий.
1. Введите данные в ячейки А1:С11, как показано на рис. 26.
2. Дополнительно: введите Инструмент анализа: Корреляцияв ячейку Е1.
3. В меню Данные выберите Анализ данных. В диалоговом окне Анализа Данных в списке Инструментов анализа выберите Корреляцию и нажмите Готово. Появится диалоговое окно Корреляции, как показано на рис. 27.
4. Укажите местоположение данных в строке ввода Входной интервал, включая метки (А1:С11), в части окна для входных данных. Проверьте, что данные сгруппированы по столбцам и отмечен пункт Метки в первой строке.
5. Щелкните по кнопке Выходной интервал в части окна Параметры вывода, затем щелкните по соседней строке ввода и укажите левую верхнюю ячейку области для результатов инструмента (Е2).
6. Нажмите ОК. Выходные данные появятся в ячейках Е2:Н5, как показано на рис. 26.
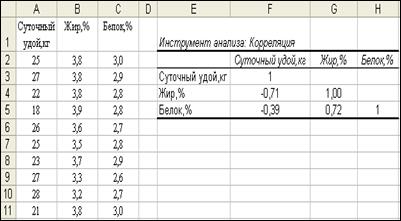
Рис. 26. Попарные корреляции
Рис. 27. Диалоговое окно корреляции
Выходные данные представляют собой матрицу трех попарных корреляций. Между суточным удоем и содержанием жира отмечена отрицательная корреляция (r= -0,71) средней силы, между суточным удоем и белком (r= -0,39) также отмечена отрицательная корреляция, но значительно меньшей силы. В то же время между показателями химического состава молока (жир и белок) установлена достаточно сильная положительная зависимость (r=+0,72).
ПРОСТАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ
Простая линейная регрессия используется для определения линейного уравнения, описывающего среднее соотношение двух переменных. В этом разделе описываются два метода построения линейной регрессии: команда Добавить линию тренда и инструмент анализа Регрессии. Перед тем как аппроксимировать данные прямой, следует изучить график рассеяния, получаемый способом, описанным ранее. Если точки на графике лежат примерно на одной прямой, то можно применить методы, описываемые в этом разделе. Если же точки не лежат на прямой и имеют другой рисунок, то следует использовать нелинейные методы.
В этом разделе анализируются данные о яйценоскости кур-матерей и кур-дочерей, описанные в примере 1 в начале раздела "Двумерные числовые данные".
Добавление линейного тренда
Точечная диаграмма была построена ранее и приведена на рис.22.
Точки на рис. 22 расположены примерно на одной прямой, поэтому можно построить линейный тренд (линию). Такую прямую часто также называют прямой среднего соотношения. Следующие шаги описывают добавление линейного тренда на график и форматирование результатов.
1. Повторите действия, описанные ранее при построении рис.22.
2. Выделите ряд данных, щелкнув по любой точке данных на рисунке. Точки должны стать подсвеченными, в строке Имя появится текст «Ряд1», а в панели формул строка, показывающая, что выделен РЯД.
3. В меню Макет выберите кнопку Линия тренда или щелкните правой кнопкой по ряду данных и выберите Добавить линию тренда в контекстном меню.
4. Перейдите на вкладку диалогового окна Формат линии тренда, как показано на рис. 28.
Рис.28. Диалоговое окно линии тренда
5. На вкладке Параметры линии трендаа щелкните по пиктограмме Линейная.
6. На вкладке Название аппроксимирующей (сглаженной) кривойвыберите Автоматическое. Убедитесь, что пункт Пересечение кривой с осью Y в точке не отмечен. Включите опции Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации (R2), как показано на рис. 29, и нажмите ОК.
7. Щелкните на уравнении и перетащите область Формата подписей в правый верхний угол окна диаграммы (рис.30).
Рис. 29.Параметры линии тренда
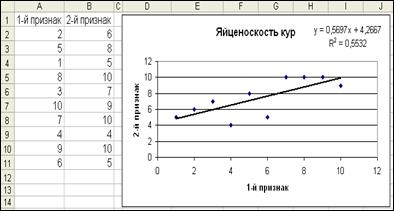
Рис. 30. Окончательная линия тренда на графике
Интерпретация линии тренда
Ответ на вопрос «Каково среднее соотношение» можно получить, изучая уравнение аппроксимации у = 0,5697х + 4,2667, которое можно переписать в виде у = а + b×x или:
Яйценоскость кур-дочерей (2-й признак) = 4,2667 + 0,5697 ´ Яйценоскость кур-матерей (1-й признак).
Более подробное описание коэффициентов уравнения см. в разделе "Прямолинейная регрессия, ее коэффициент и уравнение" первой части пособия.
Наклон, или обратный коэффициент регрессии, 0,5697 показывает среднее изменение переменной Y (2-й признак) при единичном изменении переменной X (1-й признак). То есть в данном случае, если число яиц, снесенных курами-матерями за 10 дней, изменится на одно яйцо (1-й признак), то яйценоскость кур-дочерей изменится на 0,5697 яйца (второй признак).
Одним из самых распространенных способов ответить на вопрос «На сколько хорошо приближение» является исследование значения R2, которое измеряет долю изменения зависимой переменной Y и выражается через переменную X и линию регрессии. Здесь значение R2 равно 0,5532 и показывает, что примерно 55,3% изменений числа снесенных курами яиц может быть выражено линейной моделью. Возможно, остальные 44,7% колебаний могут быть выражены через другие параметры объектов в регрессионной модели с многими параметрами.
Инструмент анализа регрессия
Команда Добавить линию тренда в результате выдает аппроксимирующую прямую, уравнение и R2. Для получения дополнительной информации о зависимости двух переменных руководствуйтесь следующими инструкциями по использованию инструмента анализа Регрессия.
1. Расположите данные, как и ранее, по столбцам: переменная X слева, переменная Y справа. Освободите место для результатов регрессионного анализа справа от данных по крайней мере 16 столбцов. (Удалите график или подвиньте его далеко вправо.)
2. В меню Данныес выберите Анализ данных. В диалоговом окне Анализа данных выберите Регрессия и нажмите ОК. Появится диалоговое окно Регрессия, как показано на рис. 31.
3. Входной интервал Y: укажите или введите ссылки на диапазон со значениями зависимой переменной, включая метку над данными (столбик В).
4. Входной интервал X: укажите или введите ссылки на диапазон со значениями независимой переменной, включая метку над данными (столбик А).
5. Метки: Отметьте этот пункт, так как Входные интервалы X, Y включают в себя подписи сверху.
6. Константа - ноль: данную опцию включите только в том случае, если вы хотите, чтобы прямая регрессии проходила через начало координат (0,0).
7. Уровень надежности: Excel автоматически выводит 95% доверительный интервал для коэффициентов регрессии. Для получения других доверительных интервалов выделите этот пункт и введите уровень значимости.
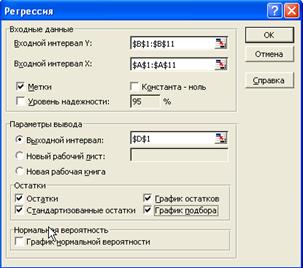
Рис. 31. Диалоговое окно Регрессия
8. Параметры вывода (расположение результатов): щелкните по кнопке Выходной интервал и в строке справа укажите или введите ссылку на левый верхний угол области шириной примерно в 16 столбцов, где будут располагаться итоговые результаты и диаграммы. В случае если вы хотите, чтобы результаты располагались на отдельном листе, щелкните по кнопке Новый рабочий лист.
9. Остатки: включите эту опцию для получения подобранных значений (предсказанных Y) и остатков.
10. График остатков: отметьте этот пункт, чтобы получить диаграмму остатков для каждого значения переменной X.
11. Стандартизированные остатки: отметьте этот пункт для получения нормированных остатков. Данная операция позволяет легко увидеть значения, выходящие за пределы.
12. График подбора: отметьте этот пункт для получения точечной диаграммы входных значений Y и подобранных значений Y относительно переменной X. Данная диаграмма похожа на график с добавленной линией тренда, описанной ранее.
13. После выбора всех опций и введения ссылок нажмите ОК. Должны появиться итоговые результаты (рис.32, 33) и диаграммы (рис.34, 35). Разрядность чисел уменьшена для лучшего восприятия данных.

Рис. 32. Итоговые результаты инструмента Регрессия
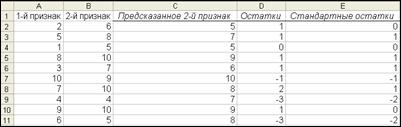
Рис.33. Перемещенные остатки
14. Для того чтобы сделать все результаты видимыми, измените ширину столбцов, выполняя раздельное выделение.
15. Чтобы облегчить результаты сравнения, переместите (расположите) данные об остатках рядом с исходными данными, измените разрядность значений и сдвиньте вправо блок "Выводы итогов".
Интерпретация регрессии
Смещение и наклон аппроксимирующей прямой представлены в столбце результатов «Коэффициенты» на рис. 32. Коэффициент У-пересечение 4,2667 является постоянным членом уравнения линейной регрессии, а коэффициент 1-й признак 0,5697 является наклоном. Уравнение регрессии выглядит так:
2-й признак (яйценоскость дочерей) = 4,2667+ 0,5697 ´ 1-й признак (яйценоскость матерей).
Предсказанное число снесенных курами яиц за 10-дневный период, приведенные в остатках на рис. 33 и иногда называемые подобранными значениями, являются результатами оценивания яйценоскости каждой курицы с помощью уравнения регрессии. Остатки равны разнице между фактическими и подобранными значениями. Например, первая курица снесла за 10 дней 2 яйца. В среднем можно ожидать, что ее дочь снесет за тот же период 5 яиц, но реально она снесла 6 яиц. Остаток для данного объекта равен 6 - 5 = +1 яйцо. Реальная яйценоскость оказалась на 1 яйцо выше ожидаемой. Остатки также называют отклонениями или ошибками.
Обычно для ответа на вопрос «Насколько хорошо приближение» используются следующие четыре характеристики: стандартная ошибка, R2, t-статистика и анализ дисперсии. Стандартная ошибка 1,644 приведена в ячейке Е7 рис. 32 и выражается в тех же единицах, что и зависимая переменная – яйценоскость кур-дочерей (2-й признак).
Значение R-квадрат, приведенное в ячейке Е5 рис. 32, характеризует долю изменений зависимой переменной, описываемых кривой регрессии. Данное число должно быть в пределах от нуля до единицы и часто выражается в процентах. В нашем примере приблизительно 55,3% колебаний яйценоскости кур описывается моделью с площадью в качестве независимой переменной линейного уравнения.
Значения t-статистики в ячейках G17:G18 рис. 32 являются частью проверок гипотез о коэффициентах регрессии. Например, данные о яйценоскости 10 кур-матерей и их дочерей могут рассматриваться как выборка из большей совокупности. Нулевая гипотеза состоит в том, что зависимость отсутствует, то есть коэффициент регрессии совокупности для 1-го признака (яйценоскость кур-матерей) равен нулю, а следовательно, изменение яйценоскости кур-матерей не влияет на количество снесенных яиц курами-дочерями. Коэффициент регрессии выборки 0,5697 со стандартной ошибкой коэффициента (оценка ошибки выборки) 0,1810 находится на расстоянии 3,1474 ≈ 3,15 стандартных ошибок от нуля. Двустороннее р-значение 0,0137 приведено в ячейке H18 и является вероятностью получить данные результаты или что-либо более экстремальное при выполнении нулевой гипотезы. Таким образом, мы отвергаем нулевую гипотезу и заключаем, что имеется достаточно существенная зависимость между яйценоскостью кур-матерей и их дочерей.
Диаграммы регрессии
В случае простой линейной регрессии инструмент анализа строит две диаграммы: график остатков и график подбора. Данные диаграммы располагаются вверху листа, справа от итоговых результатов.
График подбора прямой приведен на рис. 34. Данная диаграмма подобна графику с добавленной линией тренда (см. рис.30), за исключением того, что предсказанные значения на диаграмме отображаются маркерами без соединяющей их линии.

Рис. 34. Первоначальный график подбора прямой
График остатков (после изменения заголовка и прозрачности формата области построения)представлен на рис. 35.
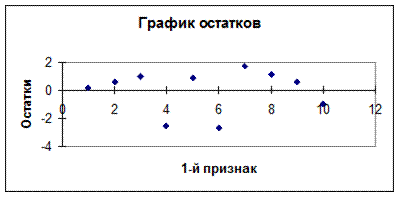
Рис. 35. График остатков регрессии
Данный тип диаграмм применяется для определения, является ли приемлемой форма функционала аппроксимирующей кривой. Если график остатков имеет случайный рисунок, то линейное приближение является удовлетворительным. Если же график остатков имеет определенную структуру, то может потребоваться дополнительное моделирование.
Если имеется только переменная X (простая регрессия), то график остатков выглядит так, как если бы аппроксимирующая прямая на рис. 34 стала горизонтальной. В данном случае график остатков имеет достаточно случайный рисунок, и можно принять, что линейное приближение является удовлетворительным.
ДИСПЕРСИОННЫЙ АНАЛИЗ
В разделе описываются инструменты дисперсионного анализа и проверки равенства дисперсий двух выборок. Эти методы для проверки гипотез используют F-распределение (F- критерий)..
Однофакторный дисперсионный анализ
Однофакторный дисперсионный анализ используется для проверки гипотезы, что средние двух или более совокупностей равны. Данный критерий предполагает, что совокупности нормально распределены, имеют одинаковые дисперсии и случайные выборки независимы. Данный критерий подходит для полностью рэндомизированной модели.
В качестве примера возьмем данные из табл. 31 первой части пособия. В данном случае изучается влияние фактора возраста кур на массу сносимых ими яиц. Принимается предположение, что все три средние совокупности равны. Альтернативной гипотезой является утверждение, что хотя бы одно из средних отличается от остальных. Данные, представленные на рис. 36, являются случайной выборкой по десять значений из каждой совокупности.
Следующие шаги описывают построение диаграммы изменения массы яиц в зависимости от возраста кур и средних для трех возрастов.
1. Введите метки и данные, как приведено на рис. 36. Чтобы удобно расположить название признака, введенного в ячейку В1, выделите ячейки В1:D1, щелкните правой мышкой по выделению, выберите Формат ячеек | Ячейки | Выравнивание, отметьте Объединение ячеек и нажмите ОК. То же самое повторите с ячейками B3:D3.
2. Выделите ячейку В14. Введите формулу =СРЗНАЧ(В4:В13).В результате получится 48,9. Выделите ячейку В14 и скопируйте в ячейки С14 и D14.
3. Введите метки Возраст курв ячейку F1 и Масса яйцав G1.

Рис. 36. Данные для однофакторного дисперсионного анализа
4. Введите цифру 1 в ячейку F2. Выделите ячейку F2, щелкните по маркеру заполнения в правом нижнем углу (черный квадрат) и перетащите вниз к ячейке F11.
5. Так же, как и на предыдущем шаге, введите цифру 2 в ячейку F12 и скопируйте ее в F12:F21. Введите 3 в ячейку F22 и скопируйте ее в ячейки F23:F31.
6. Выделите данные для возраста 200 дней в ячейках В4:В13. Щелкните правой кнопкой на выделенном поле и выберите Копировать в контекстном меню. Выделите ячейку G2. Щелкните правой кнопкой и выберите Вставить в контекстном меню.
7. Повторите действия, описанные в предыдущем пункте, три раза, чтобы скопировать данные для возраста 300 и 400 дней из ячеек С4:С13, и D4:D13в ячейки G10, G18 и G26 соответственно. Результат должен выглядеть, как на рис. 36.
8. Выделите ячейки F1:G31 и щелкните по кнопке Вставка, выберите тип диаграммы Точечная.
9. Выберите диаграмму (щелкните в любом месте диаграммы), выберите в основном меню пункт Конструктор/Выбрать данные,в окне Выбор источника данных щелкните Добавить. Щелкните по строке Имя и введите Среднее; нажмите дважды клавишу Tab, чтобы содержимое строки Значения Y оказалось выделенным; выделите В14:D14 на листе. Нажмите ОК. (Если значения X не указаны для ряда данных точечной диаграммы, то Excel использует натуральные числа для X.)
10. Выберите пункт Макет в основном меню на вкладке/ Название диаграммы ивведите Масса яиц в зависимости от возраста курв качестве названия диаграммы, Возраст, днидля оси категорий (X) и грамм для оси значений (Y). На вкладке Сетка уберите все отметки. Нажмите Готово.
11. Щелкните на пункт Макет/ Область построения, выберите Дополнительные параметры области построения | Заливка | Нет заливки. Цвет границы – сплошная линия.
12. Дважды щелкните по вертикальной оси. В диалоговом окне Формат оси на вкладке Шкала уберите отметку с пункта Минимальное значение авто и введите фиксированное значение 45. Нажмите ОК.
13. Чтобы подготовить пространство для меток на горизонтальной оси, выделите заголовок оси X (Возраст, дни), щелкните слева от текста и нажмите Enter.
14. Щелкните у границы диаграммы (в области диаграммы) так, чтобы не выделить текстовые элементы. Щелкните по панели формул и наберите 200.После того как вы нажмете Enter, текст появится на диаграмме. Подведите курсор к границе текста так, чтобы он превратился в четыре стрелки. Щелкните и перетащите текст на место под самым левым рядом данных.
15. Повторите предыдущий шаг для получения меток возраста 300 и 400.
18. Щелкните правой мышкой по ряду данных Средние. В контекстном меню выберите Изменить тип диаграммы для ряда… / График. Нажмите ОК.
Результаты показаны на рис.37.
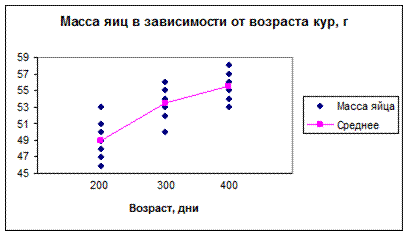
Рис.37. Диаграмма
Чтобы выполнить анализ дисперсии, введите данные, как показано на рис. 39 (ячейки A1:C11). В меню Данные выберите Анализ данных. В появившемся окне Анализ данных дважды щелкните по пункту списка Однофакторный дисперсионный анализ. Заполните строки диалогового окна, как показано на рис. 38, и нажмите ОК.
Результаты появятся в ячейках F1:L16, как показано на рис. 39. Отформатируйте число десятичных знаков.
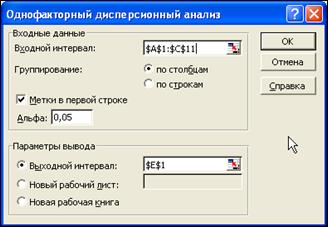
Рис.38. Окно однофакторного дисперсионного анализа
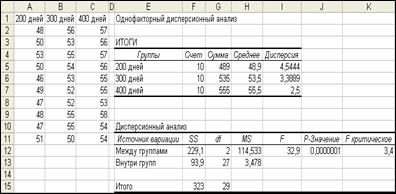
Рис. 39. Результаты однофакторного дисперсионного анализа
Таблица Дисперсионный анализ внизу рис. 39 подытоживает расчеты критерия (сравните ее с таблицами 32 и 33 в первой части пособия). Общая дисперсия 30-и значений вычисляется с использованием суммы квадратов (SS) и относится к вариации внутри и между группами. Средние квадраты (MS) являются двумя оценками дисперсии совокупностей, вычисленными делением SS на соответствующее число степеней свободы (df). Статистика F в ячейке I12 является отношением двух оценок дисперсий (114,533 : 3,478).
Если нулевая гипотеза справедлива (все три средние совокупностей равны), то оценки дисперсии совокупности должны быть приблизительно равны, а отношение F близко к единице. Если же хотя бы одно из средних существенно отличается от остальных, то вариация между группами будет большой и отношение F существенно больше единицы. Критерий дисперсионного анализа является односторонним.
Полученная F-статистика 32,9 превосходит значение критического правостороннего критерия 3,4 с 95% уровнем значимости. Таким образом, мы можем отвергнуть нулевую гипотезу равенства средних совокупностей. Следовательно, в изучаемой популяции с возрастом существенно увеличивается масса яйца.
ДВУХФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ С ПОВТОРЕНИЕМ
В этом разделе описывается двухфакторный анализ дисперсии с повторениями, который используется для оценки результатов двух испытаний. Данный критерий также подходит в случае изучения воздействия двух полностью случайных факторов на результативный признак.
В качестве примера используем данные табл. 34 из первой части пособия. Изучалось влияние трех уровней кальция (3,7%, 4,0% и 4,5%) и трех уровней аскорбиновой кислоты (без добавок витамина, 50 мг и 100 мг) на толщину скорлупы яиц кур-несушек.
Расположите данные на листе, как показано на рис. 40, чтобы выполнить анализ дисперсии.
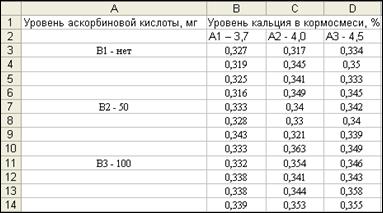
Рис.40. Двухфакторный дисперсионный анализ с повторениями
В меню Данные выберите Анализ данных. В диалоговом окне Анализа данных дважды щелкните по пункту Двухфакторный анализ данных с повторениями в списке Инструментов анализа. Заполните строки в появившемся диалоговом окне в соответствии с рис. 41 и нажмите ОК. Значение "Число строк" зависит от количества наблюдений в градации второго признака (в данном случае B) внутри градации признака А.
Результат появится в ячейках F1:L36, как показано на рис. 42.
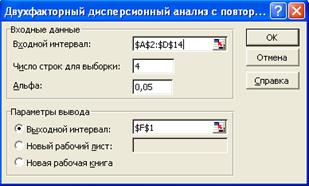
Рис. 41.Диалоговое окно двухфакторного анализа дисперсии
Таблица Дисперсионный анализвнизу рис. 42 подытоживает вычисления для проверки критерия.
Общая дисперсия 36-и значений складывается из вариации, помеченной Выборка (фактически по Рядам, уровень кальция в кормосмеси, %), вариации по Столбцам (фактически по Строкам, уровень аскорбиновой кислоты, мг), вариации Взаимодействия (конкретная комбинация уровней кальция и аскорбиновой кислоты) и вариации трех значений Внутри каждой комбинации.
Имеется три отдельных критерия проверки гипотез, соответствующих следующим факторам: время уровень кальция в кормосмеси, % (Выборочная), уровень аскорбиновой кислоты, мг (Столбцы) и их комбинация (Взаимодействие). В каждом критерии, если нулевая гипотеза об отсутствии влияния фактора справедлива, то показатель F должен быть близок к единице. Если же эффект ненулевой, то отношение F будет существенно больше единицы.
Вычисленные F статистики для уровня кальция в кормосмеси, % (4,7) и уровня аскорбиновой кислоты, мг (6,9) превосходят значения критического (табличного) критерия F (соответственно 3,4 и 3,4) для 95% уровня значимости. Следовательно, мы можем отвергнуть нулевую гипотезу об отсутствии влияния уровня кальция и уровня аскорбиновой кислоты в кормосмесях на толщину скорлупы яиц кур-несушек и сделать вывод о достоверном влиянии изучаемых факторов на толщину скорлупы.
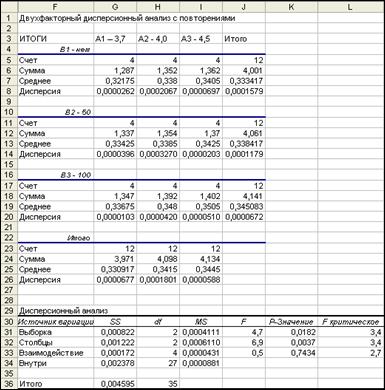
Рис. 42.Результаты двухфакторного анализа дисперсии с повторениями
Так как значение фактического критерия F по совместному влиянию двух факторов оказалось незначительным (0,5) и было меньше F-критического (2,7), можно сделать вывод о несущественном влиянии совместного действия факторов.
График взаимодействия факторов
График взаимодействия является полезным визуальным инструментом определения эффектов взаимодействия. Следующие шаги показывают, как построить график средних (расчет основывается на данных, представленных на рис.40 и 42).
1. Введите метки в ячейки В17:D17 и A18:A20, как показано на рис. 43. Скопируйте средние значения из ячеек G7:I7 в ячейки B18:D18, из ячеек G13:I13 в ячейки B19:D19, из ячеек G19:I19 в ячейки B20:D20.
2. Выделите ячейки A17:D20 и щелкните по пункту Вставка. Выберите тип диаграммы График, вид График с маркерами, и нажмите ОК. Выберите пункт Макет / Сетка /Горизонтальные линии сетки/ Нет. Введите названия диаграммы и осей, как показано на рис. 44.
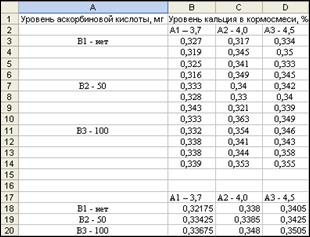
Рис.43. Данные для построения графика взаимодействия факторов
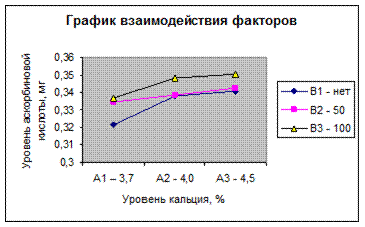
Рис. 44. График взаимодействия факторов по средним величинам
На графике взаимодействия, показанном на рис. 44, линии практически не пересекаются, показывая, что взаимосвязь двух факторов незначительна (этот вывод и приведен в первой части пособия). Если бы эффект взаимодействия был велик, то линии бы пересекались.
ЧАСТЬ 3. ЗАДАЧИ ДЛЯ УПРАЖНЕНИЙ
Тема: Средняя арифметическая величина ( 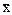 ), показатели ее разнообразия (S, С, V).
), показатели ее разнообразия (S, С, V).
1. Изучена живая масса телят холмогорских помесей при рождении (в кг):
Составьте вариационный ряд и изобразите его на графике. Какую надо взять величину классового промежутка? Рассчитать , S, V.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|