- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Техника расчета 5 страница
При более ответственных исследованиях необходимо при меньшем значении l считать, что распределение частот различается существенно.
Если фактическое значение l меньше первого стандартного значения, соответствующего Р = 0,95, во всех случаях можно считать различие между распределениями недостоверным. Если фактическое значение больше третьего стандартного его значения (Р = 0,999), во всех случаях можно считать различие между распределениями достоверным.
Пример. При оценке инкубационных качеств яиц определялась степень выраженности мраморности скорлупы. В зависимости от степени выраженности мраморности скорлупы яйца распределялись по баллам мраморности: 0,1,2,3,4,5. Для сравнения отдельных хозяйств по выраженности мраморности скорлупы получаемого в них яйца был применен расчет критерия лямбда. Для этого составлена таблица распределения частот. Определив максимальную разность накопленных частот, производим следующий расчет по приведенным формулам:
lI-II = 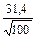 =
= 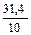 = 3,14 lI-II = 3,14
= 3,14 lI-II = 3,14
lI-III = 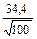 =
= 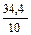 = 3,44 lI-III = 3,44
= 3,44 lI-III = 3,44
lII-III = 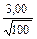 =
= 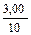 = 0,30 lII-III = 0,30
= 0,30 lII-III = 0,30
lst = 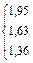
Распределение яиц по мраморности скорлупы из хозяйства "Tursio Lima" (I) достоверно отличается от такового в хозяйствах "Eduardo Rosabal"(II) и "Patrisio Pais"(III) (P>0,999).
Распределение яиц по мраморности скорлупы между хозяйствами "Eduardo Rosabal" и "Patrisio Pais" не показывает достоверного различия (Р<0,95).
В случае, если рассчитывается достоверность расхождения в распределениях с неодинаковым числом дат и классов, критерий лямбда вычисляется по формуле:
l = 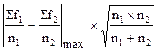 .
.
Таблица 18
Таблица распределения частот при расчете критерия лямбда (пример)
| Баллы мраморности | Хозяйства | Накопленные частоты | Разность накопленных частот | |||||||
| Tursio Lima fI | Eduardo Rosabal fII | Patrisio Pais fIII |
||||||||
| å fI | S fII | å fIII | å fI - å fII | å fI - å fIII | å fII - å fIII | |||||
| 0,3 | 0,3 | 1,0 | ||||||||
| - | 4,3 | 5,7 | 99,7 | 99,7 | 99,0 | 0,7 | 0,7 | |||
| 9,7 | 36,8 | 37,7 | 99,7 | 95,4 | 93,3 | 4,3 | 6,4 | 2,1 | ||
| 67,4 | 47,3 | 45,0 | 90,0 | 58,6 | 55,6 | 31,4 | 34,4 | 3,0 | ||
| 20,3 | 10,0 | 8,6 | 22,3 | 11,3 | 10,6 | 11,0 | 11,7 | 0,7 | ||
| 2,3 | 1,3 | 2,0 | 2,3 | 1,3 | 2,0 | 1,0 | 0,3 | 0,7 | ||
| - | - | - | - | - | - | - | ||||
РАСЧЕТ ЧИСЛЕННОСТИ ВЫБОРКИ, ДОСТАТОЧНОЙ ДЛЯ ДОСТОВЕРНОСТИ РЕЗУЛЬТАТА
При планировании эксперимента очень важно знать количество объектов, необходимых для отбора в группу, чтобы получить достоверные результаты. Для этого производится расчет численности выборки (или объема выборки), необходимой и достаточной для получения достоверных значений. В простом выражении применяемая для этого расчета формула имеет следующий вид:
n = 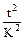 ,
,
где n - объем выборки в планируемом исследовании; t - число сигм, соответствующее показателю вероятности, достаточной в планируемом исследовании; K = 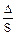 - допустимая неточность в данном эксперименте, выраженная в сигмах;
- допустимая неточность в данном эксперименте, выраженная в сигмах; 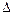 =
= 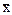 -
- 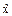 - допустимая неточность в определении генеральной средней по ее выборочной средней, т. е. допустимая разность, отличающая выборочную среднюю от генеральной величины.
- допустимая неточность в определении генеральной средней по ее выборочной средней, т. е. допустимая разность, отличающая выборочную среднюю от генеральной величины.
Для расчета объема выборки "n" по указанной формуле в качестве исходных величин необходимо хотя бы приближенно знать значения генеральной средней ( 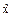 ), выборочной средней (
), выборочной средней ( 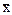 ) и квадратического отклонения (S) для изучаемого признака. Эти величины могут быть известны из данных предварительных исследований или по литературным источникам. При этом разница
) и квадратического отклонения (S) для изучаемого признака. Эти величины могут быть известны из данных предварительных исследований или по литературным источникам. При этом разница 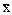 -
- 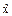 может быть достаточно большой. При наличии данных о максимальном и минимальном значениях изучаемого признака величина сигмы может быть получена путем деления размаха на 5 (на 6 или 7 в зависимости от объема выборки) .
может быть достаточно большой. При наличии данных о максимальном и минимальном значениях изучаемого признака величина сигмы может быть получена путем деления размаха на 5 (на 6 или 7 в зависимости от объема выборки) .
В случае полного отсутствия каких-либо предварительных данных показатель точности устанавливается ориентировочно. Для предварительных исследований может быть принята величина K » 0,3-0,5, для исследований средней точности - К » 0,1-0,3, для исследований повышенной точности - К » 0,1.
Показатель вероятности t для большинства биологических исследований принимается как t=1,96; Р=0,95. Для исследований, к которым предъявляется повышенная требовательность, может быть принято t=2,58; Р=0,99. В особо ответственных случаях принимается t=3,30; Р=0,999.
Пример. Требуется рассчитать, какое количество яиц следует отобрать в выборку для анализа с целью получения достоверных данных по толщине скорлупы. Известно на основании предыдущих исследований, что в среднем толщина скорлупы от птицы изучаемого кросса в аналогичных условиях содержания составляла 0,325 мм ( =0,325), квадратическое отклонение S=0,025, допустимая неточность, отличающая выборочную среднюю от генеральной средней ( 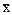 - ), может быть принята равной 0,012 (
- ), может быть принята равной 0,012 ( 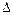 = 0,012). Производим расчет:
= 0,012). Производим расчет:
К = = 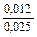 » 0,5; К = 0,5
» 0,5; К = 0,5
n = 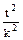 ; принимаем t = 2,0 при Р = 0,95
; принимаем t = 2,0 при Р = 0,95
n = 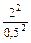 =
= 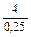 = 16; n = 16 яиц.
= 16; n = 16 яиц.
При принятом значении допустимой неточности и 95% уровне вероятности необходимо отобрать в выборку 16 яиц для получения достоверных данных по толщине скорлупы.
При повторных исследованиях требования к аналитическим данным могут быть повышены, для чего принимается 99% уровень вероятности при значении t=2,58. В этом случае получаем следующие результаты:
К= 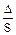 = = 0,5; К = 0,5
= = 0,5; К = 0,5
n = 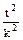 при P = 0,99 t = 2,58
при P = 0,99 t = 2,58
n = 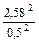 =
= 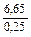 =26,6 »27; n = 27 яиц.
=26,6 »27; n = 27 яиц.
При 99% уровне вероятности для получения достоверных данных в выборку необходимо отобрать 27 яиц.
Если в исследовании предполагается сравнить две выборки и определить достоверность разности выборочных средних величин, то при одинаковом объеме сравниваемых групп применяется следующая формула расчета объема выборки:
n = 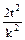 .
.
Как видно, эта формула отличается от предыдущей тем, что объем планируемой выборки удваивается.
Пример. Если применить эту формулу к предыдущему примеру, расчеты будут выглядеть следующим образом:
при 95% уровне значимости (t = 2,0)
К = = = 0,5; К = 0,5
n = = 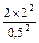 =
=  = 32 яйца ;
= 32 яйца ;
При 99% уровне значимости (t = 2,58); К = 0,5
n = = 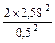 =
= 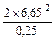 = 53 яйца .
= 53 яйца .
При желании уменьшить ошибку репрезентативности вдвое нужно в четыре раза увеличить объем выборки.
КОРРЕЛЯЦИОННЫЕ СВЯЗИ. КОЭФФИЦИЕНТ ПРЯМОЛИНЕЙНОЙ КОРРЕЛЯЦИИ
В биологических исследованиях нередко возникает необходимость изучить отдельные признаки в их взаимосвязи, проследить, в каких соотношениях находятся изменения одного признака с изменениями другого.
Взаимосвязи двух признаков хорошо известны в физике и математике. В пределах этих наук взаимосвязи определены совершенно точно: площадь треугольника определяется его высотой, длина окружности или площадь круга - величиной его радиуса, угол преломления светового луча определяется плотностью среды и т.д.
В этих случаях при изменении одного признака на определенную величину другой признак также изменяется на совершенно определенную величину. Каждому значению одного признака соответствует конкретное значение другого признака
Такие зависимости называются функциональными.
В природе на биологические объекты воздействуют очень много факторов, из которых отдельные невозможно учесть. При этом каждый фактор оказывает своеобразное воздействие на биологический объект. В этой связи у биологических объектов связь между двумя признаками никогда не может быть совершенно четкой, точно определенной, она смазывается в той или иной степени, модифицируется, ее не всегда просто обнаружить. При этом каждому определенному значению одного признака может соответствовать не одно значение второго признака, а целое распределение этих значений. В отличие от явлений, наблюдаемых в физике и математике, это связи совершенно другого рода. Их называют корреляционными связями или корреляцией.
Примерами выраженных корреляционных связей могут быть: масса тела птицы и масса яйца - более тяжелая птица, как правило, несет яйца большей массы; уровень яичной продуктивности птицы и расход корма на 1 кг яичной массы - чем выше продуктивность, тем ниже расход корма на производимую продукцию; грудной угол соответствует лучшему развитию мясных качеств птицы; плотность яйца положительно коррелирует с толщиной скорлупы. Положительная корреляционная связь может отмечаться между содержанием жира и белка в молоке коров. Уровень жирномолочности отрицательно коррелирует с величиной удоя у коров.
Поскольку при корреляционных связях существует распределение значений признаков, зависимость одного признака от другого не бывает точной, корреляция может иметь различную степень выраженности - от полной независимости до очень сильной связи. Помимо того, корреляции могут быть различными по своему направлению - прямыми (положительными) и обратными (отрицательными). При прямой связи направление изменения результативного признака совпадает с направлением изменения признака-фактора. При обратной связи направление изменения результативного признака противоположно направлению изменения признака-фактора. Между массой птицы и массой яйца, как правило, наблюдается прямая, или положительная, корреляция. Между уровнем продуктивности и расходом корма на единицу прироста имеется обратная, или отрицательная, корреляция.
По форме связи делят на линейные (прямолинейные) и нелинейные (криволинейные) связи.
Линейная связь отображается прямой линией; криволинейная - кривой (параболой, гиперболой и т. п.). При линейной связи с возрастанием значения факторного признака происходит равномерное возрастание (убывание) значения результативного признака. При криволинейной связи с возрастанием значения факторного признака возрастание (убывание) результативного признака происходит неравномерно (гиперболическая форма связи) или же направление его изменения меняется на обратное (параболическая форма связи).
Для измерения степени выраженности корреляции применяются различные показатели. Однако наиболее широко используется коэффициент корреляции.
При полных связях, когда изменения обоих изучаемых признаков строго соответствуют друг другу и корреляционная связь превращается в функциональную, коэффициент корреляции достигает своего максимального значения, равного 1 (полная связь). При прямых или положительных (полных) связях r = +1; при обратных или отрицательных полных связях r = -1.
Область допустимых значений линейного коэффициента корреляции от -1 до +1. При отсутствии связей коэффициент корреляции равен 0. Предельные значения коэффициента корреляции (r= +1; r= -1; r= 0) на практике встречаются очень редко. Обычно значения r находятся между нулем и положительной или отрицательной единицей. При этом считается, что корреляция сильная при значении r= 0,75, средняя - при r= 0,50, слабая - при r= 0,25.
Для расчета коэффициента корреляции разработаны разнообразные рабочие алгоритмы в зависимости от условий расчета - для малых и больших выборок, при малозначных или многозначных вариантах.
Исходя из этого может применяться та или иная схема расчетов (или алгоритмы решения). Однако все они дают одинаковый результат, и применение того или иного пути решения определяется удобством вычислений.
Основная формула для расчета коэффициента корреляции имеет
следующий вид:
r = 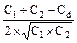 ,
,
где С - сумма квадратов центральных отклонений или дисперсия, причем C1 - для ряда первого признака; C2 - для ряда второго признака, Сd - для ряда разностей значений первого и второго признаков.
Вычисление коэффициента корреляции для малочисленных выборок при малозначных датах (способ разниц)
Наиболее постой алгоритм расчета коэффициента корреляции -расчет в малочисленных выборках при вычислении разницы между значениями первого и второго признаков. Наряду с простотой решения он отражает сущность расчета коэффициента корреляции, общую для всех случаев.
Пример.
1-й признак - число яиц, снесенных 10 курами за 10 дней.
2-й признак - число яиц, снесенных за те же 10 дней их сестрами (табл.19).
Таблица 19
| x1 | x2 | x12 | x22 | d=x2 – x1 | d2 | n=10 | Признак | d | |
| Sхi
(Sхi)2 (Sхi)2 n Sхi2 Ci | |||||||||
| 302,5 | 547,6 | 36,1 | |||||||
| -1 | |||||||||
| 82,5 | 48,4 | 36,9 | |||||||
| r = | |||||||||
| -1 | |||||||||
| +19 | |||||||||
Сi = 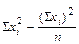 ; С1 = 385-302,5=82,5 С2 = 596-547,6=48,4
; С1 = 385-302,5=82,5 С2 = 596-547,6=48,4
Сd = 73-36,1=36,9
r = 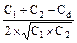 =
= 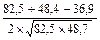 =
=  =
= 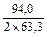 =
= 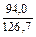 =+0,74
=+0,74
r = +0,74
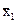 =
= 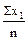 =
= 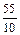 =5,5; =5,5
=5,5; =5,5
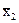 =
= 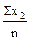 =
= 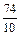 =7,4;
=7,4; 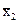 =7,4
=7,4
S1 = 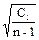 =
= 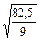 =3,03; S1 = 3,03
=3,03; S1 = 3,03
S2 = 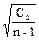 =
= 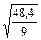 =2,32; S2 = 2,32
=2,32; S2 = 2,32
Вычисление коэффициента корреляции с применением способа произведений
Этот метод наиболее употребим для малых выборок и при возможности легко перемножить даты первого и второго признаков. Метод удобен также при работе с калькулятором. При наличии счетной техники с достаточной разрешающей способностью значимость вариант может быть довольно большой (двухзначные, трехзначные, четырехзначные даты) и им можно пользоваться также для расчета в больших выборках.
В настоящем примере разбирается тот же случай, что и в предыдущем алгоритме, но с применением формул для способа произведений (табл. 20).
Таблица 20
| x1 | x2 | x12 | x22 | x1´x2 | n=10 | Признаки | p | Формула | |
| Sхi
(Sхi)2 (Sхi)2 n Sхi2 Ci | Sx1´Sx2
Sx1´Sx2 n
S(x1´ x2) a - в | ||||||||
| в=407 | |||||||||
| 302,5 | 547,6 | ||||||||
| а=454 | |||||||||
| 82,5 | 48,4 | +47 | |||||||
| r = | |||||||||
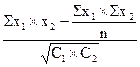
r = 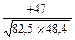 =
= 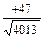 =
= 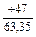 =+0,74.
=+0,74.
Составление корреляционной решетки при вычислении коэффициента корреляции для больших групп
Указанные в предыдущих разделах методы расчета коэффициента корреляции при отсутствии вычислительной техники трудно использовать, если возникает необходимость обрабатывать достаточно большой объем цифрового материала. В подобных ситуациях применяются способы расчета, первым и обязательным этапом для которых является составление корреляционной решетки.
Для расчета коэффициента корреляции между средней живой массой кур (признак 1) в семьях линии белый леггорн и средней массой сносимых ими яиц (признак 2) в качестве примера используется материал, представленный ниже.
Таблица 21
Исходные данные живой массы кур и масса сносимых ими яиц, г.
| живая масса | |||||||||
| масса яйца | |||||||||
| живая масса | |||||||||
| масса яйца | |||||||||
| живая масса | |||||||||
| масса яйца | |||||||||
| живая масса | |||||||||
| масса яйца | |||||||||
| живая масса | |||||||||
| масса яйца |
Порядок составления корреляционной решетки следующий.
В первую очередь необходимо определить число классов и величину классовых промежутков для каждого ряда признаков.
1. Число классов ("ч") ориентировочно может быть 6-8 при небольшом объеме выборки и 10-12 при значительном числе дат. Для точного его определения возможно применить формулу:
число классов ч = 1 + 3,3´lg n .
В нашем случае:
ч = l+3,3´lg40 = 1+3,3´1,60 = 1+5,28 = 6,28 Округлив полученный результат, принимаем величину "ч" равной 7.
2. Определяем классовый промежуток (к) и границы классов для первого признака. Максимальное значение равно 1844, минимальное -1505, соответственно размах 1844-1505=339. Отсюда классовый промежуток:
к =  = 48,3 » 50 .
= 48,3 » 50 .
Исходя из этого, целесообразно границы классов обозначить как 1501-1550; 1551-1600; 1601-1650 и т.д.
3. Для второго признака максимальное значение равно 59, минимальное - 53, размах равен 7, классовый промежуток - 1.
4. На основании полученных данных составляется корреляционная решетка. При этом необходимо выдержать определенный порядок обозначения классов: классы первого признака обозначаются по верхней горизонтальной грани решетки слева направо в возрастающем порядке, классы второго признака - по левой грани в порядке возрастания дат снизу вверх (табл. 22).
Таблица 22
 1 1
| 1501-1550 | 1551-1600 | 1601-1650 | 1651-1700 | 1701-1750 | 1751-1800 | 1801-1850 |
 1 1
|  1 1
|  1 1
| 1
|  1 1
| |||
| 1
|  1 1
| 1
|  1 1
| ||||
| 1
|  3 3
|  3 3
| 1
| 1
| |||
 1 1
|  4 4
|  2 2
| 1
| ||||
| 1
|  2 2
| 2
|  1 1
| 1
| |||
| 1
|  2 2
| 2
| |||||
| 1
| 1
|
5. При заполнении корреляционной решетки каждая пара значений разносится по классам. Ячейки корреляционной решетки заполняются частотами при помощи точек и черточек, так же как и при составлении вариационных рядов. Попадание каждого случая в определенную ячейку производится в зависимости от значений первого и второго признаков.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|