- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Сведения об авторах 3 страница
3. Базовые механизмы ядра.
4. Менеджеры ресурсов (диспетчеры).
5. Интерфейс систем вызовов (API-функции).
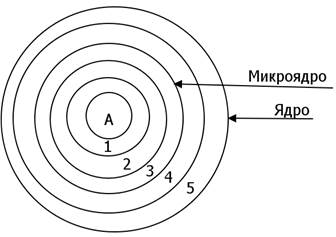
Рис.3.3. Многослойная структура ОС.
Задачи 1 и 2 слоев – скрыть детали аппаратуры, обеспечить идентичность работы программиста с аппаратурой разных изготовителей.
1, 2 и 3 уровни составляют микроядро ОС. Базовые механизмы ядра, а также уровни 1 и 2 не принимают никаких решений, а исполняют отдельные функции работы с аппаратурой.
На 4 уровне и выше уже принимаются решения. Каждый менеджер (памяти, устройств ввода- вывода и др.) ведет учет своих ресурсов, выделяет их при необходимости процессам, перераспределяет.
Самый верхний слой выполняет вызовы, запросы программ, так называемые системные вызовы. Раньше они назывались командами ОС.
Например, вызов read (fd, buffer, count) обозначает команду чтения из файла fd в область buffer количества слов count. То есть читает буфер и образует кучу. Системные вызовы существенно влияют на работу программ.
В ядре выделяют микроядро – первые три слоя. Это связано с тем, что микроядро составляет неделимую часть ОС. Вместе с четвертым и пятым слоем оно образует ядро ОС.
С ядром взаимодействуют:
· - приложения пользователей;
· - библиотеки процедур;
· - утилиты - программы, реализующие отдельные задачи управления ОС;
· - системные программы (компилятор, загрузчик и др.).
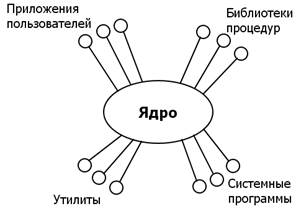
Рис.3.4. Окружение ОС.
Утилиты, например, обслуживают файловую систему, архивируют данные, генерируют случайные числа и т.д.
3.6. История ОС
Начало для создания ОС положила фирма Microsoft выпуском своей дисковой операционной системы MS-DOS. ОС была невелика по объёму и размещалась на гибком магнитном диске, вставляемом в дисковод А.
MS-DOS представляет собой монолитную ОС – ядро, ещё не распавшееся на слои. Ядро окружали согласно рис.3.4 программы пользователей (1), библиотеки подпрограмм (2), утилиты (3) и системные программы (4).
Работала ОС довольно плохо. Неприятности заключались в том, что при любом сбое программы пользователя или драйвера внешнего устройства ОС «рушилась». Приходилось снова загружать ОС и начинать работу вновь.
Стали искать пути выхода из этой ситуации. Для этого выделили пользовательский режим, куда поместили всё окружение (1 – 4), а для работы ядра ввели защищённый режим - привилегированный, так называемый режим ядра. В результате надежность работы ОС повысилась, но она стала работать медленнее. Ведь для вызова любой системной функции приходилось производить переключение из пользовательского режима в режим ядра и обратно, для чего требовалось затратить дополнительное время τ на каждое переключение.
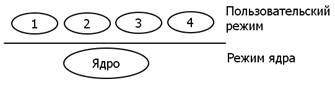

Рис.3.5. Выделение режимов пользовательского и защищенного.
Дальнейшим шагом в совершенствовании ОС стало введение микроядерной архитектуры. Все драйвера вынесли в пользовательский режим. Те слои, которые раньше назывались менеджерами, стали называть серверами и тоже вынесли в пользовательский режим. Таким образом, в защищенном режиме осталось только микроядро.
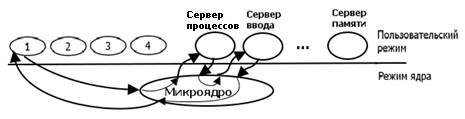
Рис.3.6. Работа микроядра.
Надежность ОС повысилась, но быстродействие еще более снизилось. Если пользовательская программа обращается к серверному процессу, который, в свою очередь, требует операции ввода вывода, то при каждом обращении к микроядру требуется переход от пользовательского к защищенному режиму и обратно, что требует дополнительных затрат времени. Таим образом при обращении к серверному процессу требуется затратить дополнительно 6τ времени.
В настоящее время микроядерный режим в чистом виде не используется из-за медленности его работы. Больше используют гибридный режим, в котором серверные процессы оставляют в микроядре, а сами драйвера выносят в пользовательский режим.
4. Процессы и потоки
Процесс – это программа в ходе ее выполнения. Процессу выделяется память со своими разделами (рис.3.1) одним из разделов является блок управления процессом (БУП). Иначе его называют дескриптором процесса или объект- процессом.
4.1. Состояние процесса
Поскольку процессов в ВМ выполняется много, то каждый процесс большое время проводит в очередях. При этом он переходит из одного состояния в другое. Обобщенная схема включает в себя 5 состояний. Таких состояний может быть и больше. Например, в UNIX их 13.
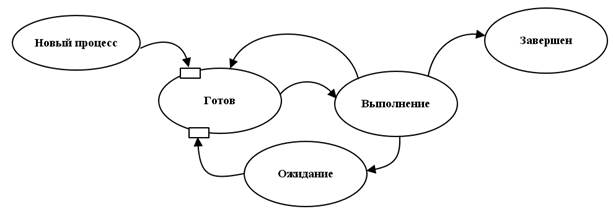
Рис.4.1. Схема состояний процесса.
Состояние «новый» - программа принята к исполнению, для нее выделена память с необходимыми разделами. Состояние «готов» - это очередь готовых процессов. Здесь работает диспетчер кратковременный планировщик. Его задача выбрать из списка готовых процессов 1 и перевести его в состояние выполнения. Ни один из процессов не может долго занимать центральный процессор. Поэтому каждому процессу выделяется квант времени, по окончанию которого процесс переводится в состояние готов – в очередь готовых процессов.
Еще один вариант – ожидание ввода- вывода. Здесь своя очередь процессов ожидающих некоторого события (реакции пользователя, освобождения устройства ввода – вывода и др.). После совершения события процесс снова переводится в состояние готов. Здесь работает долговременный диспетчер планировщик. Он отличается от кратковременного, управляющего выделением квантов времени, тем, что работает по своему алгоритму. Он может быть построен с учетом разных подходов (например, приоритетов).
Из чего состоит БУП?
· PID – идентификатор процесса;
· состояние процесса;
· указатель на родительский процесс, если процесс порожден другим процессом;
· счетчик команд;
· регистры ЦП, используемые процессом;
· ввод – вывод, указывает, откуда процесс загружен и куда выводит информацию;
· текущие параметры (насколько загружен ЦП, как используется куча ит.д.).
Рассмотрим, как производится переключение одного процесса на другой. Пусть всего имеется два процесса, чередующиеся в фазе выполнения.
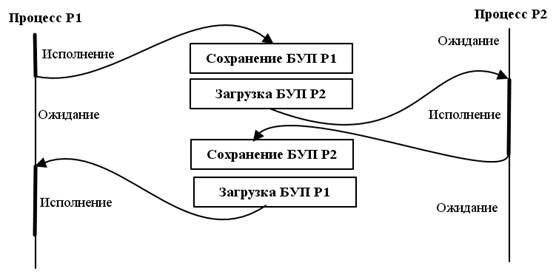
Рис.4.2. Переключение процессов.
В простейшем случае переключение процессов иллюстрируется рис. 4.2. На самом деле процедура переключения процессов сложнее. По существу, есть периоды времени, когда не выполняется ни один из процессов.
4.2. Потоки
При выполнении какого-либо процесса в нем могут присутствовать ветви, способные к параллельному выполнению. Например, при умножении матриц параллельно можно перемножать различные элементы матриц.
Ранее вычислительный процесс рассматривался как последовательное выполнение команд, и повышение быстродействия достигалось, в основном, путем повышения тактовой частоты генератора ВМ. В 2004 году фирма Intel пришла к выводу, что предел повышения тактовой частоты скоро будет достигнут, и повышать быстродействие ВМ следует путем разработки многоядерных процессоров и применения распараллеливания операций.
В первых параллельных алгоритмах над задачей распараллеливания работали программисты. Естественно, это приводило к тому, что одни процессоры были перезагружены, а другие простаивали без работы. Выход нашли путем перекладывания задач распараллеливания операций на ОС, применяя, в том числе языки высокого уровня (ЯВУ), ориентированные на многопоточную обработку данных.
В настоящее время все ЯВУ делятся на однопоточные и многопоточные. К однопоточным относятся ранние ЯВУ (Паскаль, Фортран, Си, Си++ в первых своих редакциях).
Многопоточные ЯВУ стали разрабатываться ещё до появления многоядерных процессоров. К таким языкам относится, прежде всего, Java. Он с самого начала был многопоточным. Так же многопоточными являются С#, Python, а также серия ЯВУ с расширением .Net: Visual C++ Net, Visual Basic Net. Эти языки уже при компиляции используют многопоточную модель вычислений.
Как ОС использует многопоточность?

Рис.4.3. Управление потоками в процессах.
На рис. 4.3 приведена модель управления потоками со стороны процессов, выполняемых на ВМ. Показано, что ядро производит управление процессами 1 и 2, ничего не зная о потоках, созданных внутри этих процессов. Первый процесс создал три потока, второй – четыре потока. Все эти потоки выполняются лишь тогда, когда выполняется соответствующий процесс. Выполнение потоков происходит лишь на том процессоре, который выделен ОС соответствующему процессу. Внутри процессов имеются управляющие модули, которые создают таблицу потоков. Эти же модули и управляют выполнением потоков внутри процесса. Выполнение потоков и процессов осуществляется в пространстве пользователя, ядро выполняется в пространстве ядра в привилегированном режиме.
Надо отметить, что по-английски поток обозначается термином Thread, то есть «нить». Это обозначение в некотором смысле более приемлемо, поскольку оно более отличается от термина процесс и позволяет, в свою очередь, разделить поток на более мелкие составляющие – «волокна», что часто и делается ОС в настоящее время.
Чем хороши потоки по сравнению с процессами? Они используют то же адресное пространство, что и процессы, не требуют дополнительных накладных расходов при переходе от одного потока (нити) к другому потоку одного и того же процесса.
Положительным свойством управления потоками в пользовательском пространстве является то, что процессы и потоки выполняются быстро, не переходя в режим ядра. Кроме того, такой механизм можно реализовать в любой ОС.
Недостатком такого подхода является то, что все потоки одного процесса могут выполняться только на том ядре, которое ОС выделила данному процессу.
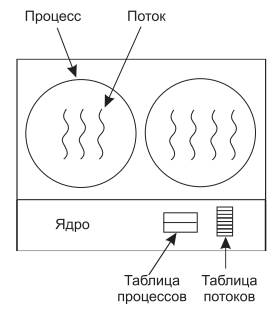
Рис.4.4. Управление потоками в ядре.
Более современный подход представлен на рис.4.4. Здесь управление потоками и процессами осуществляется в ядре ОС. То есть ядро знает о потоках каждого процесса и привлекается к их планированию и управлению ими. Такой подход позволяет смешивать управление потоками и процессами, в том числе выделять потокам одного процесса разные процессоры.
Достоинством такого подхода является то, что любой поток может выполняться на любом ядре процессора, что существенно повышает эффективность использования аппаратуры и приводит к повышению быстродействия. Недостатком такого подхода является то, что и процессы и потоки обращаются к ядру ОС, при этом увеличиваются накладные расходы на переключение пользовательского и защищенного режимов.
Вариантов осуществления управления потоками и процессами очень много. Есть очень много сложностей и неприятностей при практическом осуществлении конкретных вариантов реализации управления.
Задачи, ориентированные для выполнения на многоядерных процессорах, хуже выполняются на процессорах с малым количеством ядер. Поэтому в общем случае число потоков и количество ядер процессора должно быть согласовано. Программы на более совершенные процессоры следует оптимизировать.
В настоящее время идет интенсивная работа по поиску возможных путей решения более сложных задач. В частности, рассматривается возможность для создания потоками подчиненных потоков следующего уровня, то есть разделять «нити» на отдельные «волокна».
5. Управление памятью
По характеру использования разделяют память на виртуальную, физическую, страничную и др. Дело в том, что обычно оперативной памяти не хватает для исполняемых на ВМ процессов.
В качестве первого выхода из этого положения предложили так называемые оверлеи. Программист сам разбивал программу на части – оверлеи, очередной оверлей загружался в ОП после выполнения предыдущего оверлея. Такой подход частично решал проблему с нехваткой оперативной памяти, но создавал трудности для программистов.
Вторым выходом из положения стало использование виртуальной памяти с возложением на операционную систему задач, связанных с загрузкой в ОП необходимых для работы процессов частей виртуальной памяти с диска. При этом решалась задача обеспечения для программистов прозрачности работы с памятью. Вся работа с загрузкой в ОП частей процесса с диска и выгрузкой обратно выполнялась диспетчером памяти ОС и становилась для программистов невидимой.
Виртуальная память – это совокупность программно-аппаратных средств, позволяющих пользователю писать и выполнять на ВМ программы, объём которых превосходит имеющуюся в ВМ оперативную (физическую) память. Для этого делают следующее:
- в исходном состоянии все данные и программный код размещают на диске;
- ОС при выполнении процесса перемещает данные и программный код между диском и ОП частями таким образом, чтобы пользователь этого не замечал;
- пользователь все время работает как бы в виртуальной памяти большого объема.
Как это осуществляется на практике?
Для этого существует три метода управления памятью: страничное распределение, сегментное распределение и сегментно-страничное.
5.1. Страничное распределение.
На рис.5.1 приведена схема взаимодействия виртуальной и физической памяти. В диске данные хранятся на дорожках секторами, размер которых равен 512 байт. Поэтому размер страницы выбирают кратным этому значению: 1К, 2К, 4К, 8К. В настоящее время преимущественно используют размер страницы 4К или 8К.
Пример.
Пусть внешняя память (диск) имеет объем 1Мбайт = 220 байт. Физическая память имеет объем 16 Кбайт = 214 байт. Страница имеет объем 4 Кбайт = 212 байт. Соответственно, для адресации виртуальной памяти требуется 20 разрядов, физической памяти - 14 разрядов, смещения внутри страницы - 12 разрядов. Кроме того, отсюда следует, что физическая память содержит 22 = 4 страницы, а виртуальная – 28 = 256 страниц.
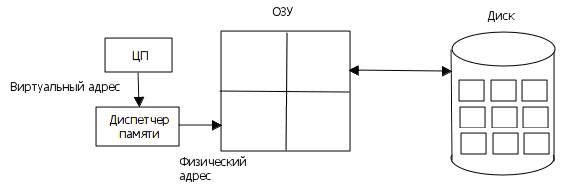
Рис.5.1. Взаимодействие виртуальной и физической памяти.
Виртуальный адрес состоит из двух частей: 8 старших разрядов – номер страницы, 12 младших разрядов – смещение в странице. Физический адрес тоже состоит из двух частей: 2 старших разряда – номер страницы, 12 младших разрядов – смещение в странице.
Пусть процессору потребовалось обратиться к байту на 9-й странице со смещением 2049. В физической памяти свободна страница номер 2, куда и будет переписана страница из виртуальной памяти. Надо определить виртуальный и физический адреса требуемого байта.
Для решения задачи надо построить шаблоны двух частей виртуального и физического адресов, преобразовать номера страниц виртуальной и физической памяти в двоичный код и записать их в свои места шаблонов, заполнив недостающие старшие разряды нулями. Затем преобразовать смещение в двоичный код и записать его в соответствующую часть шаблонов адреса, тоже при необходимости заполнив недостающие старшие разряды нулями.
В результате получим:
- виртуальный адрес 00001001 100000000001.
- физический адрес 10 100000000001.
Для преобразования виртуального адреса в физический диспетчер памяти ОС строит страничную таблицу:
| № вирт. стр. | V | R | M | A | № физ. стр. | Карта диска |
| … | ||||||
| 1001=910 | 10=210 | 3 дор.2 сект. | ||||
| … | ||||||
| 28-1= 25510 |
В таблице обозначено:
V – признак присутствия виртуальной страницы в ОП;
R – признак использования страницы. Обычно – несколько разрядов. При каждом обращении к странице значение инкрементируется. Чем больше R, тем активнее идет обращение к странице и тем важнее оставить ее в ОП при необходимости вытеснения страницы на диск;
M – признак модификации страницы. Равен 1, если страница модифицировалась, т.е. в нее производилась запись данных. При вытеснении такой страницы её необходимо сохранить на диск прежде записи на это место другой страницы;
А – признак прав доступа к странице. Обычно составляет 2 разряда.
Правила преобразования виртуального адреса в физический при страничном распределении памяти поясняется рис.5.2.
Обращение к таблице страниц может быть достигнуто быстрее при использовании буфера быстрого преобразования адреса TLB (Translation Lookaside Buffer). Если страничную таблицу хранить в памяти, то при каждом обращении к памяти надо обратиться прежде всего к таблице, т.е. требуется дополнительное обращение к памяти. Поэтому наиболее используемую часть страничной таблицы размещают в ассоциативной памяти, дорогой, но малой емкости. При этом поиск в таблице производится по определенным признакам и осуществляется до 10 раз быстрее, чем в обычной памяти.

Рис.5.2. Преобразование виртуального адреса в физический при страничной организации памяти.
Кстати, точно так же ассоциативно производится поиск в памяти переводчиком с иностранных языков. Переводчик имеет в памяти готовые переводы наиболее встречаемых фраз и выдает готовый перевод, если запрос имеется в памяти. Только в случае отсутствия нужной информации в памяти переводчик пословно переводит фразу на другой язык.
Положительными качествами рассмотренного страничного распределения памяти являются его простота и быстродействие. Недостатками являются недостаточный учет прав доступа к информации, которая передается из диска в ОП и обратно одинаковыми страницами.
Для устранения этого недостатка применяют сегментное распределение памяти.
5.2. Сегментное распределение памяти
Программиста интересует, в первую очередь, назначение информации, представленной в памяти сегментами с различными правами доступа. Поэтому сегментное распределение предусматривает передачу информации между диском и ОП целыми сегментами с одинаковыми правами доступа. При этом возможны ситуации, когда один и тот же сегмент (например, подпрограмма) используется одновременно двумя и более процессами. Поэтому не обязательно иметь много копий соответствующего кода в памяти каждого процесса, а достаточно иметь один такой сегмент в ОП и обращаться к нему из разных процессов по мере необходимости.
В случае сегментного распределения памяти для каждого процесса создается таблица сегментов, которая имеет сведения о размере сегмента, нахождении его в ОП и управляющую информацию, позволяющую определять, какой сегмент следует выгрузить из ОП при необходимости загрузки нового сегмента.
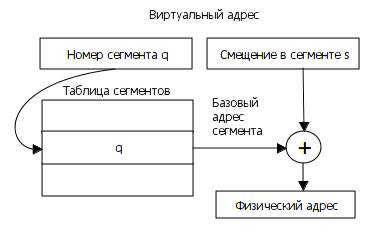
Рис.5.3. Преобразование виртуального адреса при сегментной организации памяти.
Фактически таблица сегментов аналогична таблице страниц при страничном распределении памяти. Отличие заключается в том, что сегменты имеют различный размер и находятся в виртуальной памяти не обязательно с начала страницы. Поэтому при вычислении физического адреса необходимо производить арифметические вычисления, учитывая базовый адрес сегмента в ОП и смещение внутри сегмента. Эти вычисления требуют больше времени по сравнению с вычислением физического адреса при страничном распределении, которое осуществляется посредством конкатенации номера страницы и смещения внутри страницы.
Кроме того, недостатком сегментного распределения является эффект фрагментации ОП ввиду неодинаковости размера сегментов.
Способом устранения этих недостатков является переход к сегментно-страничному распределению памяти.
5.3. Сегментно-страничное распределение памяти
Сегментно-страничное распределение памяти совмещает достоинства обоих вышерассмотренных способов распределения памяти. При этом виртуальный адрес состоит из трех составляющих: номера сегмента q, номера страницы p и смещения внутри страницы s. Перемещение информации между диском и ОП осуществляется страницами одинакового размера. Для вычисления физического адреса используются две таблицы: таблица сегментов и таблица страниц сегмента.
Схема определения физического адреса показана на рис. 5.4.
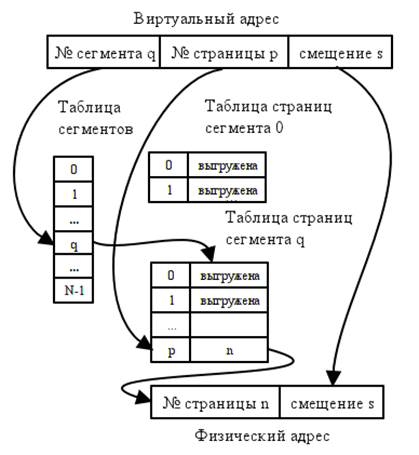
Рис.5.4. Вычисление адресов при сегментно-страничном распределении памяти.
Фрагментация памяти при таком распределении существенно уменьшается, поскольку передача информации осуществляется страницами одинакового размера, и неполной может быть только последняя страница сегмента. Кроме того, упрощается вычисление адресов, которое аналогично страничному распределению, но требует двойного обращения к памяти (используются две таблицы). По номеру сегмента выбирается таблица страниц сегмента, по номеру страницы в этой таблице выбирается номер страницы в физической памяти. Смещение внутри страницы виртуальной и физической памяти совпадают, поэтому используется операция конкатенации.
6. Файловая система
Операционная система должна обеспечить пользователям удобство работы с данными различного вида, хранящимися на диске. Для этого ОС использует вместо физического представления данных некоторую удобную для пользователей абстрактную логическую модель, представляемую в виде совокупности иерархически организованных каталогов и файлов. В результате пользователь видит данные в виде набора ярлыков или списков, выводимых на экран монитора утилитами типа Проводник (в ОС Windows).
6.1. Общие сведения о файлах и файловых системах
Файл – это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные, а также собственно хранимые в этой области данные и набор атрибутов, позволяющих ОС выполнять операции различного рода с этими данными.
Файловые системы должны обеспечить долговременное и надежное хранение информации в вычислительной системе, а также возможность совместного использования информации различными пользователями. Первое из этих свойств обеспечивается за счет хранения информации на запоминающих устройствах, не зависящих от питания, и за счет общей организации ОС, сбои в которой чаще всего не разрушают информацию, хранящуюся в файлах. Второе свойство обеспечивается понятными правилами символьного именования файлов, возможностью их группировки в иерархические структуры каталогов, наличием средств поиска файлов, создания, чтения, модификации и удаления файлов. Создатель файла или администратор имеет возможность задания прав доступа к файлам других пользователей.
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы обеспечить пользователю удобный интерфейс при работе с данными, хранящимися на диске, и обеспечить совместное использование файлов несколькими пользователями и процессами.
В широком смысле понятие "файловая система" включает:
· совокупность всех файлов на диске,
· наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске,
· комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами.
6.2. Имена файлов
Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. Еще недавно эти границы были весьма узкими. Так в популярной файловой системе FAT длина имен ограничивается известной схемой 8.3 (8 символов - собственно имя, 3 символа - расширение имени), а в ОС UNIX SystemV имя не может содержать более 14 символов. Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлу действительно мнемоническое название, по которому даже через достаточно большой промежуток времени можно будет вспомнить, что содержит этот файл. Поэтому современные файловые системы, как правило, поддерживают длинные символьные имена файлов. К примеру, файловые системы NTFS и FAT32, используемые в ОС семейства Windows, устанавливают, что имя файла может содержать до 255 символов, не считая завершающего нулевого символа.
Переход к длинным именам порождает проблему совместимости с ранее созданными приложениями, использующими короткие имена. Чтобы приложения могли обращаться к файлам в соответствии с принятыми ранее соглашениями, файловая система должна уметь предоставлять эквивалентные короткие имена (псевдонимы) файлам, имеющим длинные имена. Следовательно, важной задачей становится проблема генерации соответствующих коротких имен.
Длинные имена поддерживаются не только новыми файловыми системами, но и новыми версиями хорошо известных файловых систем. Например, в ОС Windows 95 используется файловая система VFAT, представляющая собой существенно измененный вариант FAT. Среди многих других усовершенствований одним из главных достоинств VFAT является поддержка длинных имен. Кроме проблемы генерации эквивалентных коротких имен, при реализации нового варианта FAT важной задачей была задача хранения длинных имен при условии, что принципиально метод хранения и структура данных на диске не должны были измениться.
Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющем собой последовательность символьных имен каталогов. В некоторых файловых системах одному и тому же файлу не может быть дано несколько разных имен, а в других такое ограничение отсутствует. В последнем случае операционная система присваивает файлу дополнительно уникальное имя, так, чтобы можно было установить взаимно-однозначное соответствие между файлом и его уникальным именем. Уникальное имя представляет собой числовой идентификатор и используется программами операционной системы. Примером такого уникального имени файла является номер индексного дескриптора в системе UNIX.
6.3. Типы файлов
Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги.
Обычные файлы в свою очередь подразделяются на текстовые и двоичные. Текстовые файлы состоят из строк символов, представленных в ASCII-коде. Это могут быть документы, исходные тексты программ и т.п. Текстовые файлы можно прочитать на экране и распечатать на принтере. Двоичные файлы не используют ASCII-коды, они часто имеют сложную внутреннюю структуру, например, объектный код программы или архивный файл. Все операционные системы должны уметь распознавать хотя бы один тип файлов - их собственные исполняемые файлы.
Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять операции ввода-вывода, используя обычные команды записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством. Специальные файлы, так же как и устройства ввода-вывода, делятся на блок-ориентированные и байт-ориентированные.
Каталог - это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений (например, файлы, содержащие программы игр, или файлы, составляющие один программный пакет), а с другой стороны - это файл, содержащий системную информацию о группе файлов, его составляющих. В каталоге содержится список файлов, входящих в него, и устанавливается соответствие между файлами и их характеристиками (атрибутами).
В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например:
· информация о разрешенном доступе,
- пароль для доступа к файлу,
- владелец файла,
- создатель файла,
- признак "только для чтения",
- признак "скрытый файл",
- признак "системный файл",
- признак "архивный файл",
- признак "двоичный/символьный",
- признак "временный" (удалить после завершения процесса),
- признак блокировки,
- длина записи,
- указатель на ключевое поле в записи,
- длина ключа,
- времена создания, последнего доступа и последнего изменения,
- текущий размер файла,
- максимальный размер файла.
Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой системе MS-DOS, или ссылаться на таблицы, содержащие эти характеристики, как это реализовано в ОС UNIX (рис. 6.1). Каталоги могут образовывать иерархическую структуру за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня (рис. 6.2).
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|