- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Примечание 2 страница
Пример 3. 5. Использование разрывов строк
< TITLE> Текст программы (с разрывами строк)< /TITLE>
< BODY>
function fact(int num): int< BR>
if (num> 0)< BR>
return fact(num–1)*num; < BR>
else < BR>
return 1; < BR>
end if < BR>
end function< BR>
< /BODY>
Результат обработки этого варианта HTML‑ кода приведен на рис. 3. 5.
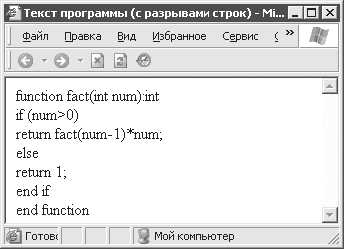
Рис. 3. 5. Использование разрывов строк
Как видно, браузер разорвал строки в указанных в тексте HTML‑ документа местах. Как и ранее, браузером проигнорированы все отступы (пробелы слева, показывающие уровни вложенности инструкций программы). Кроме того, если уменьшить ширину окна, то непомещающийся текст будет снова автоматически перенесен на следующие строки.
Для обычного текста использования < BR> вполне хватает. Однако в данном примере рассматривается программа, а не обычный текст. Чтобы полностью сохранить исходное форматирование текста (с учетом всех отступов), можно применить элемент PRE. Этот элемент задается парными тегами < PRE> и < /PRE>. Браузер учитывает все символы, которые встречаются в тексте HTML‑ документа, и выводит их на экран. Пример 3. 6 иллюстрирует использование элемента PRE для сохранения оригинального форматирования текста.
Пример 3. 6. Страница с текстом программы (использование PRE)
< TITLE> Текст программы (PRE)< /TITLE>
< BODY>
< PRE>
function fact(int num): int
if (num> 0)
return fact(num–1)*num;
else
return 1;
end if
end function
< /PRE>
< /BODY>
Результат обработки кода примера 3. 6 приведен на рис. 3. 6.
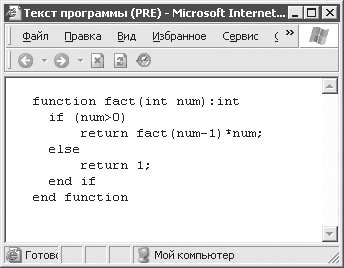
Рис. 3. 6. Текст с полным сохранением форматирования
Если внимательно посмотреть на рисунок, то можно заметить, что текст отображается моноширинным шрифтом. Таков побочный эффект использования PRE.
Запрет разрыва строки
Иногда бывает нужно не разорвать строки в тексте документа, а, наоборот, не допустить разделения некоторых слов в строках. Для этого HTML позволяет использовать неразрывные пробелы и элементы NOBR.
Неразрывный пробел можно ввести в текст HTML‑ документа с использованием соответствующей ссылки на символ: . Например:
Текст, отображаемый без переноса.
Если текст, слова которого разделены неразрывными пробелами, не помещается в окне браузера, то появится горизонтальная полоса прокрутки.
Когда необходимо выделить большой участок текста, для которого недопустим автоматический перенос слов, то целесообразнее использовать элемент NOBR. Ему соответствуют парные теги < NOBR> и < /NOBR>. Весь текст, находящийся между этими тегами, будет отображаться браузером в одной строке, например:
< NOBR>
Этот текст отображается в одной строке независимо от ширины окна браузера
< /NOBR>
Остерегайтесь создания слишком длинных неразрывных строк, поскольку необходимость горизонтальной прокрутки для прочтения таких строк только ухудшает чтение HTML‑ документа. Для вставки разрывов строк в тексте, заключенном между < NOBR> и < /NOBR>, можно использовать рассмотренный ранее элемент BR.
Переносы
При написании текста HTML‑ документа автор имеет возможность явно указать места, в которых текст может или должен переноситься на следующую строку (обычно это используется только для указания места возможного разрыва слов, потому что даже с наличием символов переноса браузер автоматически переносит целые слова так, как было рассказано ранее). Указания мест переносов в тексте достигается вставкой специальных символов переноса.
HTML предоставляет два типа переноса: простой и мягкий. Простой перенос в тексте HTML‑ документа обозначается символом –. Этот символ указывает, в каком именно месте должно разрываться слово, если оно не помещается в окне. Если же слово помещается в окне, то символ переноса все равно отображается (то есть простой перенос логично использовать только для указания дефисов в тексте, как это обычно и делается). При помощи мягкого переноса можно указать браузеру место, в котором слово можно разрывать при необходимости переноса его части на следующую строку. Мягкий перенос задается ссылкой на символ . При использовании мягкого переноса сам символ переноса (–) отображается браузером только в случае разрыва слова в указанном месте.
Ниже приведен небольшой пример использования простого и мягкого переноса в тексте HTML‑ документа (пример 3. 7).
Пример 3. 7. Использование переносов
< TITLE> Использование переносов< /TITLE>
< BODY>
Это длинное-длинное слово отображается браузером с дефисом и переносится в месте дефиса. < BR>
Слова этого текста могут разрываться в указанных местах. < BR>
< NOBR>
А этот текст не разрывается несмотря на наличие в нем символов переноса.
< /NOBR>
< /BODY>
Обратите внимание: внутри элементов NOBR (как в примере 3. 7) и PRE переносы браузером игнорируются. Однако внутри элемента NOBR можно указать место возможного переноса текста. Делается это при помощи одиночного тега < WBR> (элемента WBR соответственно).
Например:
< NOBR>
Этот текст будет разорван браузером в указанном месте при < WBR>
необходимости (когда текст не поместится в окне).
< /NOBR>
Обтекание текстом нетекстовых элементов
Далее рассмотрена еще одна возможность элемента BR, которая используется при вставке в текст документа различных изображений, таблиц и прочих нетекстовых элементов (сами эти элементы будут рассмотрены позже). Таким объектам можно задать выравнивание по правому или левому краю окна браузера (объекты с таким выравниванием называются плавающими).
Текст может обтекать плавающие объекты справа или слева. При необходимости принудительного разрыва строки с использованием элемента BR можно указать, где должна появиться следующая строка, задавая значения left, right, all или none атрибуту clear этого HTML‑ элемента. Расшифровка этих значений следующая:
• none – используется по умолчанию, означает, что новая строка начнется нормально, то есть с минимальным промежутком по вертикали и выравниванием по нужному краю;
• left – следующая строка начнется под плавающим объектом, выровненным по левому краю (если объект выровнен по правому краю, то действует аналогично none);
• right – аналогично значению left, только наоборот;
• all – следующая строка начнется под плавающим объектом независимо от края, по которому выровнен объект.
3. 3. Структурирование текста
Все, что рассматривалось ранее, – это простое физическое форматирование текста. Теперь пришло время заняться разбиением текста HTML‑ документа на логически цельные, но различные между собой части, – сформировать структуру документа. В этом разделе будут рассмотрены основные возможности структурирования документа с использованием соответствующих HTML‑ элементов, а также то, как роль текста в структуре документа влияет на его отображение.
Разбиение на абзацы
В предыдущих примерах весь текст HTML‑ документов даже при наличии в нем элементов BR воспринимался браузером как один абзац. Чтобы действительно отделить абзацы текста друг от друга, используется специальный элемент P.
Элемент P задается при помощи парных тегов < P> и < /P>. При этом следует отметить, что использование закрывающего тега < /P> считается не просто необязательным, но даже нежелательным. При отсутствии закрывающего тега концом элемента P считается начало следующего абзаца (следующий тег < P> ) или тег конца документа, если абзац последний.
Для элемента P можно задать несколько атрибутов. Список наиболее используемых атрибутов:
• align – задает горизонтальное выравнивание содержимого абзаца, может принимать значения: left (используется по умолчанию), right, center, justify;
• title – задает текст подсказки.
К тексту абзаца может применяться любое форматирование, однако оно не должно нарушать восприятие абзаца как единого целого. Обычно сами абзацы браузерами визуально отделяются друг от друга. Далее приведен небольшой пример, в котором используется разбиение текста на абзацы (пример 3. 8).
Пример 3. 8. Использование абзацев
< TITLE> Разбиение текста на абзацы< /TITLE>
< BODY>
< P title = " Первый абзац" >
Неформатированный текст
< P align = " right" title = " второй абзац" >
Текст с < B> изменением < I> начертания< /I> < /B>
< P align = " center" title = " третий абзац" >
< FONT size = " +2" face = " arial" > Текст с измененным шрифтом< /FONT>
< P align = " justify" title = " четвертый абзац" >
Текст этого абзаца автоматически выравнивается по ширине справа и слева при переносе слов
< /BODY>
При обработке приведенного HTML‑ кода получится документ, показанный на рис. 3. 7.
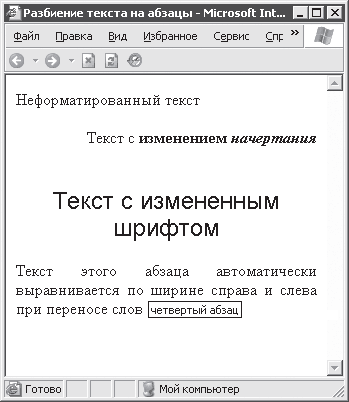
Рис. 3. 7. Использование различного оформления абзацев
При наведении указателя мыши на текст абзаца появляется подсказка, заданная атрибутом title.
Заголовки
Следующим важным этапом в структурировании HTML‑ документа является использование заголовков (в их обычном понимании) для обозначения начала больших фрагментов текста.
В HTML поддерживаются шесть видов заголовков. Им соответствуют элементы H1, H2, H3, H4, H5 и H6. Номера определяют уровни заголовков от наиболее важного (1) до наименее важного (6). Элементы H1–H6 задаются при помощи соответствующих парных тегов. Например, для задания заголовка третьего уровня можно применить следующий код:
< H3> Текст заголовка третьего уровня< /H3>
Для заголовков можно задать свойства:
• align – выравнивание текста заголовка (по умолчанию используется выравнивание по левому краю);
• title – текст подсказки.
Заголовки различных уровней обычно отображаются браузерами различными шрифтами и различного размера. При этом размер шрифта более важных заголовков обычно больше, чем размер шрифта менее важных.
На рис. 3. 8 приведен пример того, как отображаются заголовки различного уровня (HTML‑ код не приводится ввиду его чрезвычайной простоты).

Рис. 3. 8. Вид заголовков в Internet Explorer
В тексте, который заключен между тегами начала и конца заголовка, можно использовать рассмотренные ранее элементы форматирования (например, изменить шрифт). Однако это крайне не рекомендуется. Ведь стандартные заголовки придуманы именно для того, чтобы сделать похожими друг на друга HTML‑ документы различных авторов, чтобы пользователь при просмотре документа браузером не терялся в догадках относительно роли того или иного текста.
Задание типов фраз
Даже в разбитом на отдельные абзацы тексте смешаны различные по важности и смыслу участки текста. Чтобы их можно было отделить друг от друга, при написании HTML‑ документа можно пользоваться специальными элементами, задающими типы фраз в тексте (или, как еще говорят, элементами логического форматирования текста). Описания этих HTML‑ элементов приведены в табл. 3. 3.
Таблица 3. 3. Элементы задания типов фраз
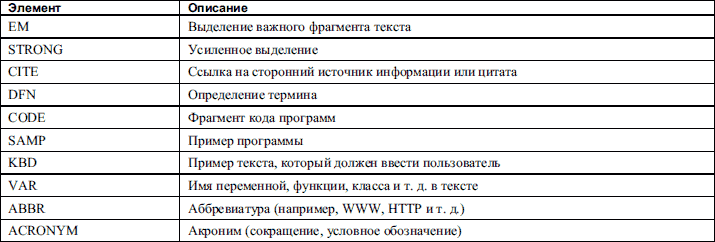
Первые два элемента используются для подчеркивания важности какого‑ либо отрезка текста. Остальные элементы используются в основном в технических текстах. Все приведенные элементы задаются при помощи соответствующих парных тегов. Текст подсказки к каждому из этих элементов задается при помощи атрибута title. Наиболее часто этот атрибут используют с элементами ABBR и ACRONYM для отображения в подсказке полной расшифровки сокращения или аббревиатуры.
Естественно, что логическое разделение текста при помощи элементов из табл. 3. 3 отражается на его представлении браузером (правда, разные браузеры могут отображать одинаковый по значению текст различным образом). В примере 3. 9 приведен текст HTML‑ документа, использующий все доступные типы фраз.
Пример 3. 9. Использование различных типов фраз
< TITLE> Использование различных типов фраз< /TITLE>
< BODY>
Обычный текст < BR>
Выделение: < EM> Важный текст< /EM> < BR>
Сильное выделение: < STRONG> Это очень важный текст< /STRONG> < BR>
Цитата, ссылка: < CITE> см. стандарт ISO 3273< /CITE> < BR>
Определение: < DFN> WWW – это... < /DFN> < BR>
Пользователь должен ввести: < KBD> Пример ввода пользователя< /KBD> < BR>
Переменная: < VAR> strText< /VAR> < BR>
Аббревиатуры: < ABBR> HTTP, WWW, FTP< /ABBR> < BR>
Сокращения: < ACRONYM> Внешпосылторг, UNIBEL< /ACRONYM> < BR>
Фрагмент программы в тексте: < CODE> CALL main< /CODE> < BR>
Пример программы: < SAMP> void main(){return; }< /SAMP> < BR>
< /BODY>
На рис. 3. 9 приведен внешний вид страницы, сгенерированной при обработке текста примера 3. 9.
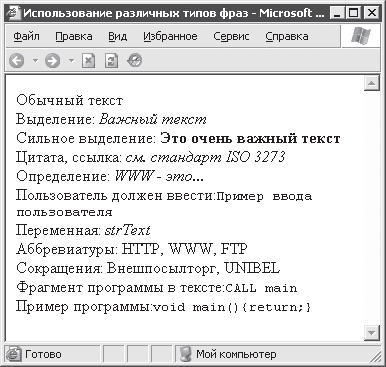
Рис. 3. 9. Внешний вид фраз различного типа
Как можно видеть из рисунка, большинство фраз различного типа отображаются браузером Internet Explorer совершенно одинаково. Не стоит полагать, что это отображение нельзя изменить. Можно использовать, например, рассмотренные ранее способы форматирования. Однако при этом польза от элементов, задающих типы фраз, становится весьма сомнительной. Для изменения внешнего текста HTML‑ элементов настоятельно рекомендуется использовать таблицы стилей, которые будут рассмотрены позже.
Стоит также отметить, что сохранить оригинальное форматирование примера программы или прочего текста внутри элемента SAMP весьма проблематично, в отличие от того же элемента PRE. Именно поэтому в примере 3. 9 текст программы выбран таким образом, чтобы он мог быть помещен в одну строку без потери его читабельности.
Цитаты
Кроме элемента CITE, для оформления цитат могут также использоваться элементы BLOCKQUOTE и Q. Для их задания используются соответствующие парные теги.
Элемент BLOCKQUTE используется для задания длинных цитат и представляет собой элемент уровня блока. При этом текст цитаты обычно оформляется браузерами как текст с дополнительным отступом.
Элемент Q является элементом уровня текста и используется для создания небольших цитат. Текст, помещенный между тегами < Q> и < /Q>, оформляется различными браузерами по‑ разному (например, может быть помещен в кавычки).
Атрибуту cite элементов BLOCKQUOTE и Q можно присвоить URI источника информации для цитаты.
Указание изменений в документе
В ряде случаев возникает необходимость изменять важное содержимое HTML‑ документа уже после того, как он опубликован (например, если речь идет о разрабатываемом законопроекте). В таких случаях практически незаменимыми являются HTML‑ элементы INS и DEL, применяемые для выделения участков текста, которые были добавлены или удалены в новой версии документа.
Элемент INS задается при помощи парных тегов < INS> и < /INS>, между которыми помещается добавленный текст. Элемент DEL задается парными тегами < DEL> и < /DEL>. В эти теги заключается текст, удаленный из новой версии документа.
Естественно, что содержимое элементов INS и DEL отображается браузерами совершенно поразному. Содержимое элемента DEL может быть, например, зачеркнутым или вообще не показываться браузером.
Элементы INS и DEL могут содержать как небольшие участки текста, так и целые разделы документа. Однако недопустимым является вложенность этих элементов друг в друга.
< INS> < DEL> Никогда так не делайте< /DEL> < /INS>
Наиболее часто используемыми атрибутами элементов INS и DEL являются следующие:
• cite – задает URI HTML‑ документа с пояснениями сделанных изменений;
• datetime – время, когда в документ были внесены изменения.
Здесь вы впервые встретились с заданием атрибуту значения даты и времени. Это значение в HTML задается в следующей форме:
ГГГГ–ММ–ДДTчч: мм: cc
Здесь ГГГГ обозначает год, ММ – месяц, ДД – день, чч – значение от 0 до 23 (час), мм и сс – значения от 0 до 59 (минуты и секунды). Кроме того, в конец значения даты и времени добавляется одна из следующих записей:
• Z – обозначает, что используется UTC‑ время (общее скоординированное время, или время по Гринвичу);
• +чч: мм или –чч: мм – обозначает, что местное время опережает или отстает от UTC на заданное количество часов и минут.
Ниже приведен пример различных вариантов задания московского времени 14 часов 5 минут 31 декабря 1997 года (с использованием местного времени и времени UTC):
1997–12–31T14: 05+03: 00
1997–12–31T11: 05Z
Контактная информация
В HTML предусмотрен специальный элемент ADDRESS, в который может заключаться различная контактная информация. Он задается при помощи парных тегов < ADDRESS> и < /ADDRESS>.
Текст внутри элемента ADDRESS может иметь произвольную структуру, однако чаще всего в него помещаются имена сотрудников организаций, ссылки на другие HTML‑ документы, телефон или адрес электронной почты контактного лица.
3. 4. Комментарии в HTML-коде
При написании достаточно сложных HTML‑ документов зачастую бывает полезно иметь возможность вставлять в исходный текст небольшие или развернутые комментарии. Добавление в сложный HTML‑ документ грамотных комментариев позволяет сэкономить уйму времени при необходимости, например, повторного редактирования документа месяц спустя.
Текст комментария помещается между символами <! – и –>. При обработке HTML‑ документа текст комментария игнорируется браузером. Комментарии могут быть как однострочными, так и многострочными:
<! – Это пример однострочного комментария –>
<! – А это
многострочный комментарий–>
Важным моментом является то, что между <! и – нельзя вставлять пробелы. Кроме того, следует избегать использования в тексте комментария двух и более символов переноса (–).
В завершение еще одно замечание. Перед опубликованием HTML‑ документа лучше удалить из исходного текста все комментарии (особенно, если автор этого документа любит оставлять себе большие подробные послания на будущее). Если объем комментариев достаточно большой, то, удалив их, можно уменьшить время загрузки HTML‑ документа с сервера.
Глава 4 Списки
В этой главе будут рассмотрены особенности введения в HTML‑ документы простых и в то же время таких удобных элементов текста, как списки. В HTML 4. 01 поддерживаются три вида списков: маркированные, нумерованные, а также списки определений. Возможно создание вложенных списков.
4. 1. Маркированные списки
Маркированные списки применяются для перечисления неупорядоченной информации. В таком списке каждый новый элемент выделяется маркером (отсюда и название списка). В HTML для обозначения маркированного списка используется элемент UL, который задается парными тегами < UL> и < /UL>. Между тегами помещаются элементы списка. Текст элементов списка начинается после тега < LI> и может заканчиваться тегом < /LI>.
С закрывающим тегом < /LI> ситуация такая же, как и с закрывающим тегом < /P>: использование его необязательно. Если тег < /LI> опустить, то текстом элемента списка считается весь текст, расположенный до следующего тега < LI> или до закрывающего тега < /UL>. Ниже приведен пример простого маркированного списка, состоящего из трех элементов.
< UL>
< LI> Первый элемент
< LI> Второй элемент
LI> Третий элемент
< /UL>
К тексту элементов любых списков можно применять рассмотренные ранее средства HTML по форматированию текста.
Рассматриваемые элементы UL и LI имеют ряд атрибутов. Специфичными атрибутами элемента UL являются следующие:
• compact – заставляет браузер показывать список более компактно (действие этого атрибута зависит от конкретного браузера);
• type – позволяет задать тип маркера списка, может принимать следующие значения: circle (круг без заливки), dict (круг с заливкой) и square (квадрат).
Атрибут type можно указывать и для нужных элементов списка LI, если понадобится изменить тип маркера только некоторых элементов списка. На рис. 4. 1 приведен пример того, как отражается задание различных значений атрибута type на отображении списка браузером.

Рис. 4. 1. Маркированные списки
Ниже приведен текст HTML‑ документа, который был обработан браузером (пример 4. 1).
Пример 4. 1. Маркированные списки
< TITLE> Маркированные списки< /TITLE>
< BODY>
Список с закрашенными круглыми маркерами
< UL>
< LI> Первый элемент
< LI> Второй элемент
< /UL>
Список с круглыми незакрашенными маркерами
< UL type = " circle" >
< LI> Первый элемент
< LI> Второй элемент
< /UL>
Список с квадратными маркерами
< UL type = " square" >
< LI> Первый элемент
< LI> Второй элемент
< /UL>
Список с разными маркерами элементов
< UL>
< LI> Закрашенный круг
< LI type = " circle" > Окружность (type = circle)
< LI type = " square" > Квадрат (type = square)
< /UL>
< /BODY>
4. 2. Нумерованные списки
Нумерованные списки применяются для упорядочения приводимых данных. При нумерации элементов таких списков могут быть использованы как арабские, так и римские цифры, буквы латинского алфавита.
Нумерованный список в тексте HTML‑ документа обозначается элементом OL при помощи парных тегов < OL> и < /OL>. Элементы нумерованного списка задаются в точности так же, как и элементы маркированного списка. Нумерованный список несколько отличается от маркированного не только внешним видом, но и набором атрибутов и их возможными значениями:
• compact – заставляет браузер отображать список компактно;
• type – задает тип нумерации элементов списка, доступные значения: 1 (используются арабские цифры, по умолчанию), I или i (большие или малые римские цифры), A или a (большие или малые буквы латинского алфавита);
• start – номер первого элемента списка (при задании start нужно учитывать тип нумерации элементов списка, например номеру 5 соответствует латинская буква E).
Атрибут start часто используется, когда нужно продолжить нумерацию предшествующего списка после отрывка текста, не являющегося элементом ни одного списка (например, после пояснения элемента предшествующего списка). В примере 4. 2 показано использование различных типов нумерации списков.
Пример 4. 2. Нумерованные списки
< TITLE> Нумерованные списки< /TITLE>
< BODY>
Нумерация арабскими цифрами
< OL>
< LI> Первый элемент
< LI> Второй элемент
< /OL>
Продолжение нумерации, но большими римскими цифрами
< OL type = " I" start = 3>
< LI> Третий элемент
< LI> Четвертый элемент
< /OL>
Новый список, нумерация большими латинскими буквами
< OL type = " A" >
< LI> Первый элемент
< LI> Второй элемент
< /OL>
< /BODY>
Списки, использованные в примере 4. 2, выглядят в окне браузера так, как показано на рис. 4. 2.
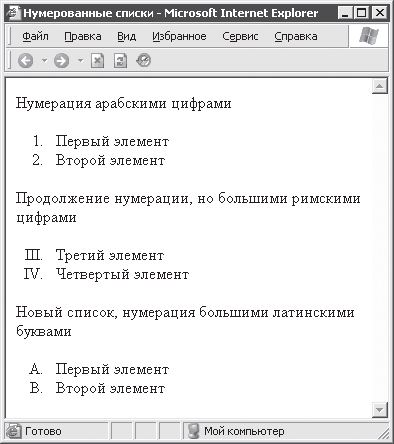
Рис. 4. 2. Нумерованные списки
Значение атрибута type можно отдельно указать для любого элемента списка. Кроме того, для элементов нумерованного списка можно задать значение атрибута value. Его действие аналогично атрибуту start элемента OL с тем лишь отличием, что он изменяет нумерацию, начиная с того элемента, для которого указано значение атрибута value. Например, задание атрибута value так, как сделано ниже в примере 4. 3, приведет к результату, который показан на рис. 4. 3.

Рис. 4. 3. Изменение нумерации внутри элементов списка
Пример 4. 3. Изменение нумерации списка
< TITLE> Изменение нумерации< /TITLE>
< BODY>
< OL>
< LI> Первый элемент
< LI value = 10> Второй элемент
< LI> Третий элемент
< LI value = 20 type = " A" > Четвертый элемент
< LI type = " A" > Пятый элемент
< /OL>
< /BODY>
Может возникнуть вопрос: что произойдет, если задать нумерацию буквами такого длинного списка, на элементы которого не хватит и всех букв латинского алфавита? Ответ таков: для нумерации элементов списка с 27‑ го элемента используются две латинские буквы (например, AA, AB, AC и т. д. ), с 703‑ го элемента используются 3 латинские буквы и т. д.
4. 3. Списки определений
Интересной разновидностью списков являются списки определений. Как можно догадаться из названия, первоначально эти списки были введены для более наглядного представления определений терминов.
Список определений задается внутри HTML‑ элемента DL (для его задания используются парные теги < DL> и < /DL> ). Каждый элемент списка определений состоит из двух частей: из термина (HTML‑ элемент DT) и определения термина (HTML‑ элемент DD). Пример текста HTML‑ документа, содержащего список определений, приведен ниже (пример 4. 4).
Пример 4. 4. Список определений
< TITLE> Список определений< /TITLE>
< BODY>
< DL>
< DT> HTML
< DD> Широко используемый язык гипертекстовой разметки
< DT> WWW
< DD> От англ. World Wide Web, глобальная сеть из соединенных между собой гипертекстовых документов
< /DL>
< /BODY>
Как можно видеть на рис. 4. 4, браузер по‑ разному отображает сами термины и определения этих терминов, причем делает это так, что сразу понятно, где определение, а где термин.
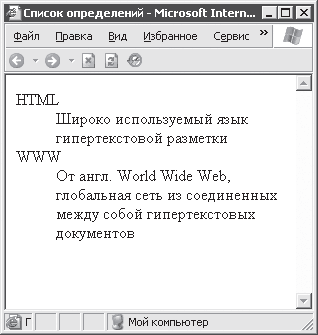
Рис. 4. 4. Список определений
Все особенности использования закрывающих тегов < /DT> и < /DD> аналогичны особенностям использования тега < /LI>, то есть, несмотря на то что эти теги определены, использовать их совершенно не обязательно.
В следующем разделе при рассмотрении особенностей создания вложенных списков будет показано, как списки определений могут повысить наглядность текста, а также подчеркнуть особую роль некоторых абзацев в общем тексте.
4. 4. Создание вложенных списков
Важной особенностью списков в HTML является та простота, с которой можно создавать списки различной вложенности, используемые для очень подробной и разветвленной классификации. На рис. 4. 5 приведен пример небольшого трехуровневого списка.
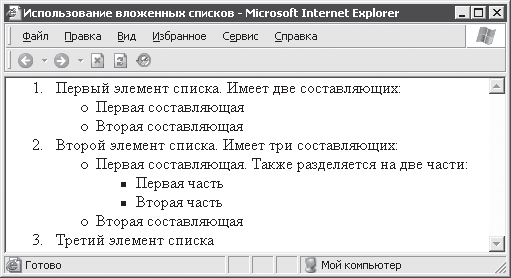
Рис. 4. 5. Вложенные списки
Из примера видно, что при вложении можно использовать списки различных типов. В данном случае в качестве внешнего списка используется нумерованный список, а в качестве вложенных списков – маркированные. Ниже приведен текст HTML‑ документа, при обработке которого браузер Internet Explorer сгенерировал страницу, показанную на рис. 4. 5 (пример 4. 5).
Пример 4. 5. Вложенные списки
< TITLE> Использование вложенных списков< /TITLE>
< BODY>
< OL>
< LI> Первый элемент списка. Имеет две составляющих:
< UL>
< LI> Первая составляющая
< LI> Вторая составляющая
< /UL>
< LI> Второй элемент списка. Имеет три составляющих:
< UL>
< LI> Первая составляющая. Также разделяется на две части:
< UL>
< LI> Первая часть
< LI> Вторая часть
< /UL>
< LI> Вторая составляющая
< /UL>
< LI> Третий элемент списка
< /OL>
< /BODY>
При рассмотрении того как браузер обрабатывает вложенные списки, можно увидеть одну интересную особенность: браузер (по крайней мере, Internet Explorer) сам заботится о том, чтобы списки различных уровней вложенности имели разные маркеры. Однако при использовании вложенных маркированных списков следует помнить, что если специально не настраивать вложенные списки при помощи атрибута type, то для списка первого уровня (не вложенного в другой список) используется маркер, соответствующий значению dict атрибута type. Для списка второго уровня используется значение circle, а для всех списков третьего, четвертого и т. д. уровней используется значение square.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|