- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
СТАТИСТИЧЕСКОЕ КОДИРОВАНИЕ СООБЩЕНИЯ
2.СТАТИСТИЧЕСКОЕ КОДИРОВАНИЕ СООБЩЕНИЯ
Заданик 2.1
Произвести статистическое кодирование буквенного сообщения, со-стоящие из Фамилии Имени Отчества студента.
Для чётного числа единиц в первых двух буквах фамилии студента – методом Шеннона-Фано, для нечётного числа единиц в первых двух буквах фамилии студента – мето-дом Хаффмана.
Показать, что полученный код является префиксным. Вычислить остаточную избыточность.
Воспользоваться вычисленными вероятностями букв из предыду-щего задания.
Решение задния 2.1
Сообщение «Чернавин Денис Леонидович».
«Ч» - 0100 0010 0111; «е» - 0100 0011 0101. Первые две буквы фамилии студента имеют десять единиц, чётное число. Поэтому производим статистическое кодирование, согласно заданию, методом Шеннона-Фано. Разместим буквы в таблице 2.3, в порядке убывания вероятности и произведём кодирование. Пробелы между словами можно не учитывать. Буквы с одинаковой вероятностью размещаем произвольно.
Представим фамилию в двоичном виде (таблица 1):
Таблица 1
| Буква ai | Вер-ть | Элементы кодовых комбинаци | Код. комб | Длина символа ai | |||||||
| и | 4/23 | ||||||||||
| н | 4/23 | ||||||||||
| е | 3/23 | ||||||||||
| в | 2/23 | ||||||||||
| д | 2/23 | ||||||||||
| о | 2/23 | ||||||||||
| ч | 2/23 | ||||||||||
| а | 2/23 | ||||||||||
| л | 1/23 | ||||||||||
| р | 1/23 | ||||||||||
| с | 1/23 | ||||||||||
H=3.27335 Бит/букву.
Hmax=log2(11)=3.4595 Бит/букву.
P=5.4%
Средняя длина одной буквы после кодирования:
 Бит/букву.
Бит/букву.
Кодирование является оптимальным, если выполняется соотношение: Lср= H.
Избыточность после кодирования:
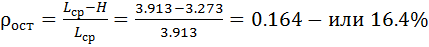 .
.
Общая длина сообщения после кодирования:
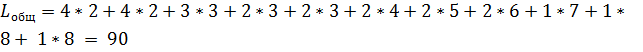 Бит.
Бит.
Данный код является префиксным, т.к. короткая кодовая комбинация не является началом более длинной(таблица 1).
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|