- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Классификация методов кодирования
1.2. Классификация методов кодирования
На рис. 1.1 дана классификация методов кодирования  . Одна из его задач - согласование алфавита сообщения с алфавитом канала. Каждый ансамбль сообщений можно кодировать разными способами. Лучший код удовлетворяет требованиям:
. Одна из его задач - согласование алфавита сообщения с алфавитом канала. Каждый ансамбль сообщений можно кодировать разными способами. Лучший код удовлетворяет требованиям:
1) приемник может восстановить сообщение источника, посланное по линии связи;
2) для представления одного сообщения в среднем нужно минимальное число символов.
Первому требованию удовлетворяют обратимые коды. В них все кодовые слова различны и однозначно связаны с соответствующими сообщениями. Экономные коды удовлетворяют второму требованию.
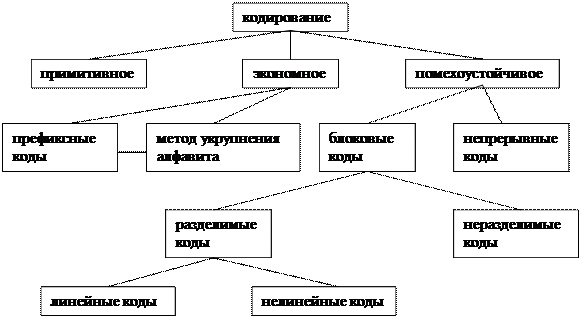 |
Рис. 1.1. Классификация методов кодирования
Целью эффективного (статистического) кодирования является повышение скорости передачи информации и приближение этой скорости к максимально возможной - пропускной способности канала связи. Согласование производительности источника сообщений с пропускной способностью канала – одна из наиболее важных задач кодирования.
Коды бывают первичные (простые или примитивные) и помехоустойчивые. Простые коды состоят из всех кодовых слов, возможных при данном способе кодирования. Превращение одного символа кодового слова в другое из-за действия помех дает новое кодовое слово. Возникает ошибка, которую нельзя обнаружить. В помехоустойчивых кодах применяют лишь часть из общего числа возможных кодовых слов. Применяемые слова называют разрешенными, остальные – запрещенными. Помехоустойчивое кодирование позволяет повысить верность передачи сообщений.
Различают кодирующие устройства (кодеры) для источника информации и для канала связи. Задачей первого является экономное (в смысле минимума среднего числа символов) представление сообщений, а задачей второго – обеспечение достоверной передачи сообщений.
Декодирование состоит в восстановлении сообщения по принимаемым кодовым символам. Декодирующее устройство (декодер) вместе с кодером образует кодек.Обычно кодек – логическое устройство.
Примитивное (безизбыточное) кодирование применяют для согласования алфавита источника с алфавитом канала. Тогда избыточность источников (см. п. 2.1), образованныхвыходом и входом кодера, одинакова. Это кодирование применяют также для шифрования передаваемой информации и повышения устойчивости работы системы синхронизации. В последнем случае правило кодирования выбирают так, чтобы вероятность появления на выходе кодера длинной последовательности, состоящей только из 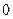 или только из
или только из 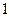 , была минимальна. Подобный кодер называют скремблером (от английского слова ²scramble² - перемешивать).
, была минимальна. Подобный кодер называют скремблером (от английского слова ²scramble² - перемешивать).
Восстановление переданного сообщения в приемнике - всегда приближенное. Часть информации, необходимая для обеспечения требуемой точности восстановления, называется существенной. Сжатие (компрессирование) сообщения (данных) - полное или частичное удаление из него (них) избыточной информации. Решение этой задачи достигается экономным кодированием. Сжатие данных дает экономию памяти запоминающих устройств и пропускной способности каналов. При экономном кодировании избыточность источника, образованного выходом кодера, меньше, чем на входе кодера. Экономное кодирование применяется в ЭВМ. Операционные системы содержат в своем составе программы сжатия данных (динамические компрессоры и архиваторы). Так, стандарт 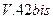 на модемы для связи между ЭВМ по телефонным сетям общего пользования включает сжатие в число процедур обработки данных (см. Приложение).
на модемы для связи между ЭВМ по телефонным сетям общего пользования включает сжатие в число процедур обработки данных (см. Приложение).
Помехоустойчивое (избыточное) кодирование применяют для обнаружения и исправления ошибок, возникающих при передаче сообщения по каналу. Тогда избыточность источника, образованного выходом кодера, больше избыточности источника на входе кодера. Это кодирование распространено в разных системах связи, при хранении и передаче данных в сетях ЭВМ, в цифровой аудио- и видеотехнике.
Число разрядов в различных кодовых словах кода может быть одинаковым или разным. Соответственно, различают равномерные и неравномерные коды. Применение равномерных кодов упрощает построение автоматических буквопечатающих устройств и не требует передачи разделительных символов между кодовыми словами. Число разрядов 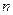 в любом кодовом слове равномерного кода - разрядность кода. Для равномерного кода число возможных комбинаций
в любом кодовом слове равномерного кода - разрядность кода. Для равномерного кода число возможных комбинаций 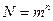 .
.
Пример 1.2.1.Примитивным равномерным кодом, используемым в телеграфии, является код Бодо с 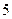 двоичными элементами в каждом слове (
двоичными элементами в каждом слове ( 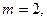
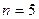 ). Полное число слов
). Полное число слов 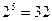 . Этого достаточно для кодирования
. Этого достаточно для кодирования 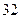 букв русского алфавита, но недостаточно для передачи сообщения, содержащего буквы, цифры и разные условные знаки (точка, запятая, сложение, умножение и т.п.). Тогда можно применить ²Международный код №2² (МТК-2) с регистровым принципом. В нем одно и то же
букв русского алфавита, но недостаточно для передачи сообщения, содержащего буквы, цифры и разные условные знаки (точка, запятая, сложение, умножение и т.п.). Тогда можно применить ²Международный код №2² (МТК-2) с регистровым принципом. В нем одно и то же 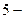 элементное кодовое слово можно использовать до трех раз в зависимости от положения регистра: русский, латинский и цифровой. Общее число разных знаков равно
элементное кодовое слово можно использовать до трех раз в зависимости от положения регистра: русский, латинский и цифровой. Общее число разных знаков равно 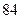 , что достаточно для кодирования телеграммы. Для передачи данных рекомендован
, что достаточно для кодирования телеграммы. Для передачи данных рекомендован 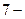 элементный код МТК-5
элементный код МТК-5 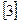 .
.
В неравномерных кодах кодовые слова различаются не только расположением символов, но и их числом. Эти коды требуют либо специальных разделительных знаков, указывающих конец одного и начало другого кодового слова, либо строятся так, чтобы никакое кодовое слово не было началом другого. Префиксные (неприводимые) коды удовлетворяют последнему условию. Заметим, что равномерный код является неприводимым.
Строение кода удобно представить в виде графа (кодового дерева), в котором из каждого узла исходит число ветвей, равное основанию кода (для двоичного кода, например, шаг вверх означает , шаг вниз - ).
Пример 1.2.2.Код Морзе - типичный пример неравномерного двоичного кода . В нем символы и применяются лишь в двух сочетаниях – как одиночные ( и ) или как тройные ( 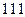 и
и 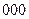 ). Сигнал, соответствующий , называется точкой, а – тире. Символ используется как знак, отделяющий точку от тире, точку от точки и тире от тире. Совокупность применяется как знак разделения кодовых слов.
). Сигнал, соответствующий , называется точкой, а – тире. Символ используется как знак, отделяющий точку от тире, точку от точки и тире от тире. Совокупность применяется как знак разделения кодовых слов.
Простой алгоритм получения неравномерных префиксных кодов предложили Шеннон и Фано. Алгоритм Шеннона-Фано для двоичного кода – следующий. Символы алфавита источника записывают в порядке без увеличения вероятностей их появления. Затем символы разделяют на 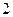 части так, чтобы суммы вероятностей символов в каждой из этих частей были примерно одинаковы. Всем символам
части так, чтобы суммы вероятностей символов в каждой из этих частей были примерно одинаковы. Всем символам 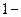 ой (
ой ( 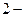 ой) части приписывают ( ) в качестве ого символа слова кода. Каждую из
ой) части приписывают ( ) в качестве ого символа слова кода. Каждую из 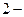 х частей (если в ней больше го символа) делят еще на две, по возможности, равновероятные части. К ним применяют то же правило кодирования. Процесс повторяют, пока в каждой из полученных частей не останется по му символу. Деление на части с ²примерно равными вероятностями² - не всегда однозначная процедура. Погрешности кодирования можно уменьшить, а код сделать более эффективным, перейдя от посимвольного кодирования к кодированию последовательностей символов сообщения методом укрупнения алфавита (см. п. 4.2).
х частей (если в ней больше го символа) делят еще на две, по возможности, равновероятные части. К ним применяют то же правило кодирования. Процесс повторяют, пока в каждой из полученных частей не останется по му символу. Деление на части с ²примерно равными вероятностями² - не всегда однозначная процедура. Погрешности кодирования можно уменьшить, а код сделать более эффективным, перейдя от посимвольного кодирования к кодированию последовательностей символов сообщения методом укрупнения алфавита (см. п. 4.2).
Пример 1.2.3.Пусть алфавит 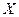 источника состоит из символов
источника состоит из символов 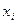 ,
, 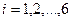 . Вероятности появления символов на выходе источника, соответственно, равны
. Вероятности появления символов на выходе источника, соответственно, равны 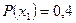 ,
, 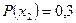 ,
, 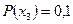 ,
, 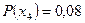 ,
, 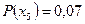 и
и 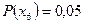 . Процедура Шеннона-Фано построения неравномерного кода без укрупнения алфавита источника задается табл. 1.1 .
. Процедура Шеннона-Фано построения неравномерного кода без укрупнения алфавита источника задается табл. 1.1 .
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|