- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Рисунок 4 – Первые три цикла перебора гиперпараметров / The first three cycles of iterating over hyperparameters
Рисунок 1 – Среднее MAE (нормализованное) на валидационных выборках перекрёстной проверки простейшего нейросетевого решения / Mean MAE (normalized) on validation samples of cross-validation of the simplest neural network solution
Как уже упоминалось ранее, обучение можно выполнить не перекрёстной проверкой, а на обычном дроблении начальной выборки на тренировочный, валидационный и тестовый срезы. Параметры срезов такие же, как и в предыдущем пункте. Обучение проводилось так же на протяжение 100 эпох, размер пакетов равен 128 единицам. Таким образом, минимальное значение показателя MAE (см. рис. 2) на валидационной выборке равно 41, 62 доллара, а переобучение (экстремум-впадина графика потерь) наступило на 91-ой эпохе. Получилось так, что ошибка при обучении на обычных срезах данных меньше, чем при обучении на разбивке по K блокам, поэтому перекрёстную проверку мы использовать в дальнейшем не будем.
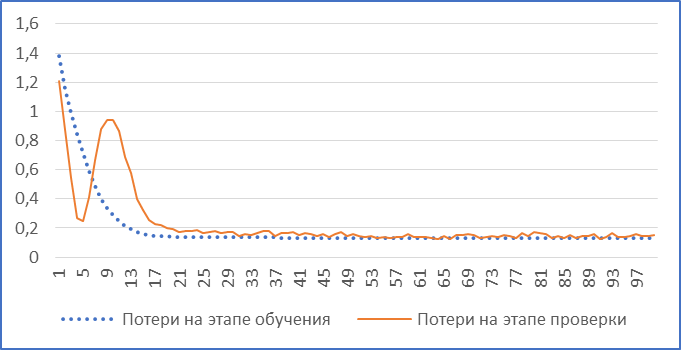
Рисунок 2 – MAE (нормализованное) на валидационной выборке без перекрёстной проверки простейшего нейросетевого решения / MAE (normalized) on a validation sample without cross-validation of the simplest neural network solution
LSTM-сеть и достижение бенчмарка. Нашей первой целью являются результаты неглубоких сетей, описанных в предыдущих пунктах, чтобы доказать, что рекуррентный слой, как минимум, лучше полносвязного, второй целью будет достижение диапазона базового решения.
Для первого случая мы просто заменим полносвязный слой на рекуррентный LSTM с гиперболическим тангенсом в качестве функции активации, остальные гиперпараметры останутся те же. По результатам обучения минимальное значение MAE на валидационной выборке (см. рис. 3) получилось равным 22, 23 доллара на 24 эпоху, что доказывает большую эффективность скалярной регрессии с помощью LSTM по сравнению с полносвязными слоями.
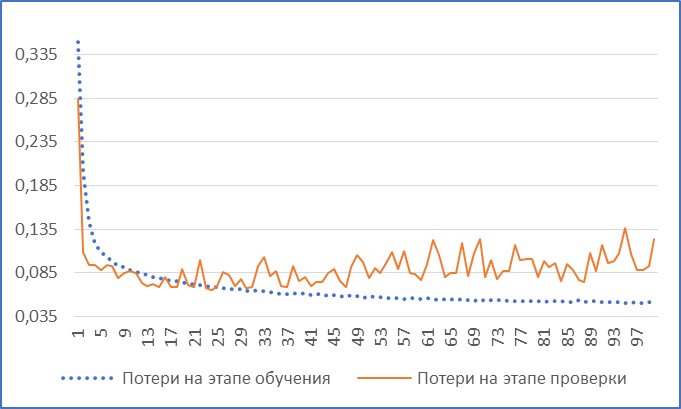
Рисунок 3 – MAE (нормализованное) на валидационной выборке первой LSTM-архитектуры, превосходящей простейший перцептрон / MAE (normalized) on a validation sample of the first LSTM architecture superior to the simplest perceptron
Однако для того, чтобы подтвердить обоснованность использования LSTM как приемлемое решение этой задачи в целом, необходимо достижение (пусть даже и теоретическое) результатов наивного решения, то есть диапазона от 11, 15 до 15, 22 долларов. Поэтому теперь нам надо реализовать подобающую оптимизацию, затрагивающую все параметры нейросети.
Вначале нам нужно выяснить в каком направлении оптимизации вообще двигаться. Представляется логичным «отмести» сразу самые серьёзные инженерные решения: количество слоёв LSTM и использование двунаправленной LSTM-сети. Тестироваться такие имплементации будут на той архитектуре, которая превзошла простейшее нейросетевое решение. При использовании двунаправленной сети мы получили минимум по MAE равный 28, 17 долларов, что хуже, чем первоначальная ошибка LSTM в 22, 23 доллара. Удвоение LSTM (во втором слое тоже 16 нейронов, как и в первом) дало MAE, равное 36, 84 долларов, удвоение входных нейронов во втором LSTM дало ошибку в 28, 59 долларов, уменьшение нейронов вдвое – 33, 59. Смена во втором слое гиперболического тангенса на популярный линейный выпрямитель ухудшило все три результата, увеличив минимальную потерю. Таким образом, мы выяснили, что слой LSTM будет один, а сеть не двунаправленная.
Теперь наша оптимизация перемещается в плоскость других гиперпараметров: эпох, входных нейронов, величины пакетов. Достаточно эффективное и быстрое решение - деревья оценок Парзена-Розенблатта[2], однако, в контексте данной работы более репрезентативной и не менее эффективной будет простой перебор с постоянным повторным воссозданием и компиляцией архитектуры на каждой итерации цикла, дабы избежать «утечек» из контрольной выборки. Перебор будет произведён по следующим элементам: эпохи – 50, 100, 200, входные нейроны – 8, 16, 32, 64, размера пакета – 64, 128. Всего было осуществлено 10 циклов перебора, это значит, что каждому конкретному образцу архитектуры соответствует 10 его одинаковых версий, это нужно, чтобы учесть возможные «всплески» минимальных ошибок из-за определённой расстановки весов внутри слоя. Для наглядного примера были взяты три первых цикла перебора (см. рис. 4), маркерами на линии минимальной ошибки отмечены экстремумы минимальной ошибки (MAE) за каждый цикл. Левая ось – ось количества нейронов и номера эпохи, на которой возник минимум ошибки, правая ось – MAE, горизонтальная ось – номер итерации цикла по перебору. Сразу видно, что каждому минимуму соответствуют 64 нейрона, пакет размером в 64 единицы (ряд пакетов не нанесён на график, чтобы не мешать наглядности), также можно заметить, что 2 из 3 экстремумов возникли в районе 100-ой эпохи.
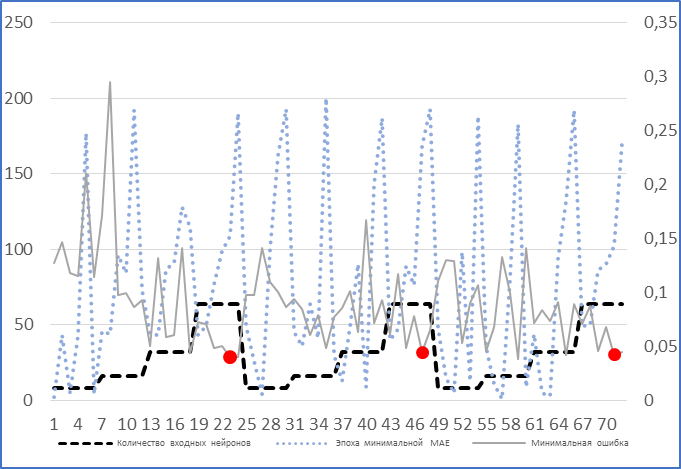
Рисунок 4 – Первые три цикла перебора гиперпараметров / The first three cycles of iterating over hyperparameters
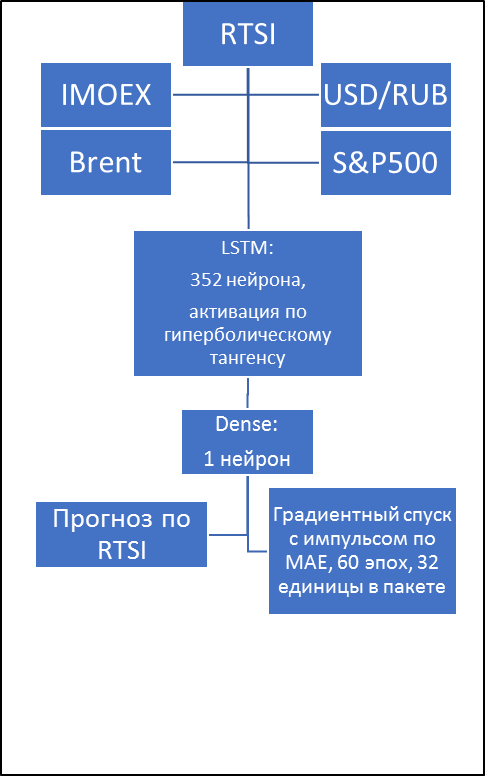
Теперь понятно, что наше основное направление оптимизации будет идти в сторону увеличения нейронов слоя (последовательного удвоения) и уменьшения пакета (последовательного деления на два), детализация этих двух параметров будет проходить после нахождения точки, в которой эффективность уже практически не прибавляется, эпохи же будут подгоняться в районы найденных минимумов MAE. Руководствуясь такими принципами получаем сеть с оптимальным размером пакета в 32 единицы, 352 нейронами и временем на обучение, равное 60 эпохам. MAE такого решения равняется 12, 66 долларов. Но эти параметры ещё не дают нам финальную структуру, хоть и вошли в диапазон бенчмарка, что уже доказывает теоретическую пригодность нашей LSTM-сети. Окончательная система будет получена после регуляризации.
Регуляризация данной модели представляет из себя подгон таких элементов, как коэффициентов рекуррентного прореживания [3] и регуляризации L1, L2. Однако, что не очевидно, ни одно средство из перечисленных не улучшило результатов. Таким образом, получено финальное рекуррентное LSTM-решение для скалярной регрессии (см. рис. 5).
> 
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|