- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Тема — Кодирование текстовой информации
19.10.2021
Информатика
Группа 13
Тема — Кодирование текстовой информации
Цели и задачи урока:
— познакомиться со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера;
— познакомиться со способом определения информационного объема текстового сообщения;
— познакомиться с алгоритмом Хаффмана.

Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Формула Хартли определяет количество информации в зависимости от количества возможных вариантов:
N=2i, где
N — это количество вариантов,
i — это количество бит, не обходимых для кодирования.
Если же мы преобразуем эту формулу и примем за N — количество символов в используемом алфавите (назовем это мощностью алфавита), то мы поймем, сколько памяти потребуется для кодирования одного символа.

N=2i, где N — кол-во возможных вариантов
i — кол-вобит, потребуемых для кодирования
Итак, если в нашем алфавите будет присутствовать только 32 символа, то каждый из них займет только 5 бит.

И тогда каждому символу мы дадим уникальный двоичный код. Такую таблицу мы будем назвать кодировочной.
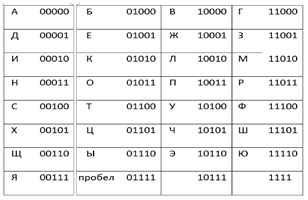
Первая широко используемая кодировочная таблица была создана в США и называлась ASCII, что в переводе означало American standard code for information interchange. Как вы видите, в таблице присутствуют не только латинские буквы, но и цифры, и даже действия. Каждому символу отводится 7 бит, а значит, всего было закодировано 128 символов.
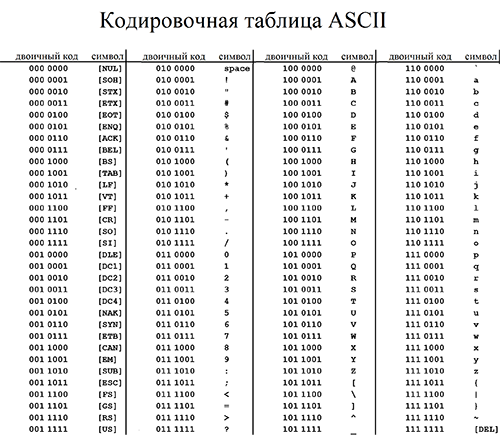
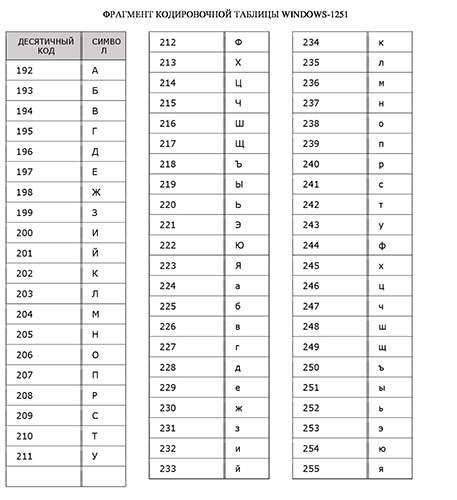
Но так как этого количества было недостаточно, стали создаваться другие таблицы, в которых можно было закодировать и другие символы. Например, таблица Windows-1251, которая, по сути, являлась изменением таблицы ASCII, в которую добавили буквы кириллицы. Таких таблиц было создано множество: MS-DOS, КОИ-8, ISO, Mac и другие:
Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:
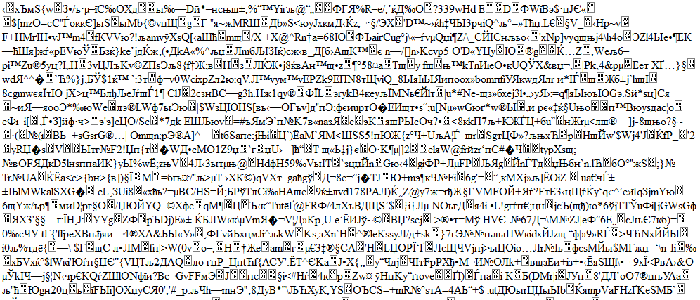
Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм Хаффмана.
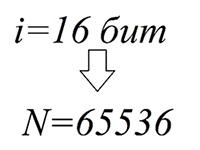
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|