- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Метод направленного перебора словаря в задаче автоматического распознавания речи на основе принципа минимума информационного рассогласования
УДК 621.372:519.72
Метод направленного перебора словаря в задаче автоматического распознавания речи на основе принципа минимума информационного рассогласования
Автоматическое распознавание речи, распознавание образов, распознавание с обучением, критерий минимума информационного рассогласования, генетический алгоритм.
А. В. Савченко
Государственный университет «Высшая школа экономики» - Нижегородский филиал
Ставится и решается задача автоматического распознавания речевых сигналов на основе принципа минимума информационного рассогласования. Предложен метод направленного перебора словаря эталонов как альтернатива методу полного перебора. Представлены результаты экспериментального исследования предложенного метода.
The Direct Search in a Dictionary’s Method in a Problem of Automatic Speech Recognition Based on Minimum Information-Mismatch Principle
Automatic speech recognition, pattern recognition, recognition with training, criterion of the minimum of information mismatch, genetic algorithm.
A.V. Savchenko.
State University “High School of Economics”, Nizhny Novgorod
The article deals with a problem of speech signals recognition based on the minimum of the informative divergent criterion. The new algorithm of direct search in a dictionary has been developed as an alternative for checking all patterns. The program and experimental results of this method have been produced.
Введение.Принцип минимума информационного рассогласования (МИР) является эффективным инструментом для решения разнообразных задач в области распознавания образов [1]. Задача автоматического распознавания речи (АРР) – одна из наиболее актуальных разновидностей такого рода задач. Существует множество подходов к ее решению. Среди них очевидный интерес представляет теоретико-информационный подход, разработанный в рамках информационной теории восприятия речи (ИТВР) [2] и основанный на упомянутом выше принципе МИР и методе обеляющего фильтра (МОФ). Его эффективность и преимущества по сравнению с другими подходами показаны в работах [3, 4] на ряде примеров из практики АРР. Между тем, далеко не все преимущества и возможности ИТВР на данный момент получили необходимое освещение и развитие. В частности, до настоящего времени практически не исследовались преимущества принципа МИР перед традиционными методами и подходами в задачах автоматического распознавания сложных речевых единиц типа отдельных (изолированных) слов или целых фраз. Исследованиям в этом актуальнейшем направлении и посвящена предлагаемая статья. В ней при учете метрических свойств решающей статистики МИР предложен метод направленного перебора (МНП) словаря эталонов как альтернатива традиционному методу сплошного перебора при проверке конкурирующих гипотез. Полученные результаты и сделанные по ним выводы рассчитаны на широкий круг специалистов в области современной теории и практики автоматической обработки речевых сигналов и распознавания образов.
Элементы ИТВР.Центральным элементом ИТВР является понятие «фонема».Под фонемой обычно понимают минимальную единицу звукового (фонетического) строя национального языка, или «элементарную речевую единицу» (ЭРЕ) [4]. Разным языкам соответствуют разные списки фонем: и по составу, и по количеству 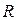 их элементов. Это базовый уровень описания каждого языка. В подтверждение можно привести пример: большинство современных речевых баз данных сопровождается транскрипцией речевых сигналов, т.е. их описанием через последовательность фонем. С другой стороны, фонетический строй языка предъявляет определенные требования к его носителям, посредством которых (и только так) этот строй и реализуется в коммуникациях. Сколько носителей – столько и разных реализаций фонетического списка национального языка. В этом проявляется краеугольная проблема вариативности устной речи. Однако, несмотря на существующие различия в реализациях каждой отдельной (r-ой) фонемы, все они воспринимаются человеком как нечто общее, иначе речь утратила бы свою информативность. Можно поэтому утверждать, что одноименные (однофонемные) реализации
их элементов. Это базовый уровень описания каждого языка. В подтверждение можно привести пример: большинство современных речевых баз данных сопровождается транскрипцией речевых сигналов, т.е. их описанием через последовательность фонем. С другой стороны, фонетический строй языка предъявляет определенные требования к его носителям, посредством которых (и только так) этот строй и реализуется в коммуникациях. Сколько носителей – столько и разных реализаций фонетического списка национального языка. В этом проявляется краеугольная проблема вариативности устной речи. Однако, несмотря на существующие различия в реализациях каждой отдельной (r-ой) фонемы, все они воспринимаются человеком как нечто общее, иначе речь утратила бы свою информативность. Можно поэтому утверждать, что одноименные (однофонемные) реализации 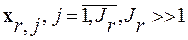 , в сознании человека группируются в соответствующие классы или речевые образы
, в сознании человека группируются в соответствующие классы или речевые образы 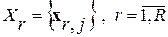 , вокруг некоторого центра – эталонной метки данного образа [2]. В ИТВР указанные эталоны определяются в строгом, теоретико-информационном смысле: речевая метка
, вокруг некоторого центра – эталонной метки данного образа [2]. В ИТВР указанные эталоны определяются в строгом, теоретико-информационном смысле: речевая метка 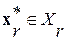 образуется информационный центр-эталон r-го речевого образа, если в пределах множества
образуется информационный центр-эталон r-го речевого образа, если в пределах множества 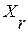 она характеризуется минимальной суммой информационных рассогласований (ИР) по Кульбаку-Лейблеру [5] относительно всех других его меток-реализаций
она характеризуется минимальной суммой информационных рассогласований (ИР) по Кульбаку-Лейблеру [5] относительно всех других его меток-реализаций 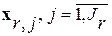 . По своей сути это статистический аналог понятия «центр массы» физического тела.
. По своей сути это статистический аналог понятия «центр массы» физического тела.
Нетрудно увидеть, что именно в понятии информационного центра (ИЦ) r-го множества реализаций 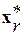 дается наиболее информативное определение соответствующей фонемы. А множество всех ИЦ
дается наиболее информативное определение соответствующей фонемы. А множество всех ИЦ 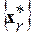 определяет исчерпывающим образом фонетический состав речевого сигнала. Одновременно становится очевидным и механизм формирования самого такого множества. Анализируемый (входной) речевой сигнал
определяет исчерпывающим образом фонетический состав речевого сигнала. Одновременно становится очевидным и механизм формирования самого такого множества. Анализируемый (входной) речевой сигнал 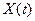 в дискретном времени
в дискретном времени 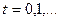 сначала разбивается на ряд последовательных сегментов данных
сначала разбивается на ряд последовательных сегментов данных 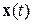 длиной в одну ЭРЕ
длиной в одну ЭРЕ 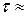 (10 – 15) mc [4]. После этого каждый полученный парциальный сигнал рассматривается в пределах конечного списка фонем
(10 – 15) mc [4]. После этого каждый полученный парциальный сигнал рассматривается в пределах конечного списка фонем 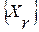 и отождествляется с той
и отождествляется с той 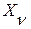 из них, которая отвечает принципу минимума величины ИР между вектором и соответствующим эталоном
из них, которая отвечает принципу минимума величины ИР между вектором и соответствующим эталоном 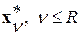 . Это стандартная [1, 2] формулировка критерия МИР в задачах автоматического распознавания образов.
. Это стандартная [1, 2] формулировка критерия МИР в задачах автоматического распознавания образов.
Критерий МИР. Задача существенно упрощается, если воспользоваться гауссовой (нормальной) аппроксимацией закона распределения речевого сигнала на интервалах его квазистационарности 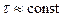 вида
вида 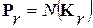 , где
, где 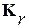 - автокорреляционная матрица (АКМ) размера
- автокорреляционная матрица (АКМ) размера 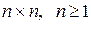 . Известно [6], что в этом случае критерий МИР является оптимальным в байесовском смысле [1]. Задача формулируется как проверка простых гипотез о законе распределения ЭРЕ. А соответствующий набор оптимальных решающих статистик может быть записан следующим образом [2]:
. Известно [6], что в этом случае критерий МИР является оптимальным в байесовском смысле [1]. Задача формулируется как проверка простых гипотез о законе распределения ЭРЕ. А соответствующий набор оптимальных решающих статистик может быть записан следующим образом [2]:
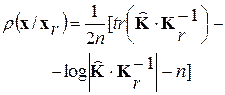 (1)
(1)
где 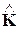 - это выборочная оценка АКМ анализируемого сигнала
- это выборочная оценка АКМ анализируемого сигнала 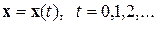 . Решение принимается в пользу гипотезы
. Решение принимается в пользу гипотезы 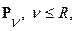 по признаку минимума
по признаку минимума 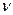 -ой решающей статистики (1), т.е.
-ой решающей статистики (1), т.е.
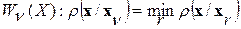 (2)
(2)
Причем, в задачах с априорной неопределенностью вместо неизвестных, в общем случае, фонемных АКМ 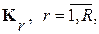 в выражение (1) подставляют их статистические оценки, которые предварительно получают по R (число фонем в списке) классифицированным выборкам речевого сигнала. Это стандартная формулировка критерия МИР с обучением.
в выражение (1) подставляют их статистические оценки, которые предварительно получают по R (число фонем в списке) классифицированным выборкам речевого сигнала. Это стандартная формулировка критерия МИР с обучением.
В работе [6] также показано, что в асимптотике, когда 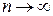 , и при распределении сигнала
, и при распределении сигнала 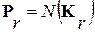 с обратной АКМ
с обратной АКМ 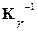 ленточной структуры оптимальный алгоритм (2) сводится к минимизации выражения
ленточной структуры оптимальный алгоритм (2) сводится к минимизации выражения
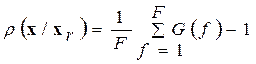 (3)
(3)
Это известная формулировка критерия МИР на основе авторегрессионной (АР) модели речевого сигнала. Здесь введено обозначение 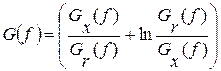 , где
, где 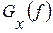 – выборочная оценка спектральной плотности мощности (СПМ) входного сигнала в функции дискретной частоты f, а
– выборочная оценка спектральной плотности мощности (СПМ) входного сигнала в функции дискретной частоты f, а 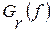 – СПМ эталона r-ой фонемы ; F – верхняя граница частотного диапазона речевого сигнала или используемого канала связи.
– СПМ эталона r-ой фонемы ; F – верхняя граница частотного диапазона речевого сигнала или используемого канала связи.
Главное достоинство АР-модели, как известно [2, 3], состоит в возможности предварительной нормировки речевых сигналов по дисперсиям их порождающих процессов. Применительно к сигналам типа ЭРЕ такая нормировка обусловлена физическими особенностями голосового механизма человека: воздушный поток на входе его модели «акустической трубы» имеет приблизительно одну и ту же интенсивность на интервалах, длительностью в целое слово или даже фразу. При учете этого свойства выражение (3) приобретает предельно простой вид [4]
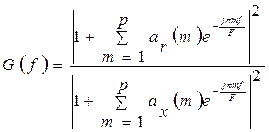 (4)
(4)
Выражения (3) и (4) представляю собой стандартную формулировку МОФ в частотной области. Здесь выражение в числителе определяет квадрат амплитудно-частотной характеристики r-го обеляющего фильтра, настроенного на r-ю фонему 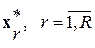 . Преимуществом такой интерпретации принципа МИР является, прежде всего, возможность его практической реализации в адаптивном варианте на основе быстрых вычислительных процедур авторегрессионного анализа, таких как метод Берга и др. [7]. Задача в общем случае сводится к двухэтапной проверке статистических гипотез. На первом этапе распознаются ЭРЕ типа отдельных фонем. На втором – слова, фразы и целые тексты как соответствующим образом структурированные последовательности разных фонем.
. Преимуществом такой интерпретации принципа МИР является, прежде всего, возможность его практической реализации в адаптивном варианте на основе быстрых вычислительных процедур авторегрессионного анализа, таких как метод Берга и др. [7]. Задача в общем случае сводится к двухэтапной проверке статистических гипотез. На первом этапе распознаются ЭРЕ типа отдельных фонем. На втором – слова, фразы и целые тексты как соответствующим образом структурированные последовательности разных фонем.
Задача первого этапа. На пути к практическому осуществлению решающего правила (2) сначала требуется определить множество всех ЭРЕ как результат линейного расчленения речевого сигнала на квазистационарные последовательности отсчетов 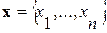 конечного объема n. Подробно указанная процедура описана в работе [8]. Разработанный в ней алгоритм сводится к последовательной проверке условия
конечного объема n. Подробно указанная процедура описана в работе [8]. Разработанный в ней алгоритм сводится к последовательной проверке условия
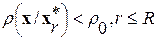 (5)
(5)
об однородности распределений вектора отсчетов 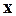 сигнала анализируемой (текущей) ЭРЕ и вектора отсчетов ИЦ каждой фонемы из текущего списка
сигнала анализируемой (текущей) ЭРЕ и вектора отсчетов ИЦ каждой фонемы из текущего списка 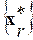 . Здесь
. Здесь 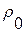 - допустимый уровень ИР в пределах однородного множества
- допустимый уровень ИР в пределах однородного множества 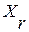 . При нарушении условия (5) в списке появляется еще одна, (R+1)-я фонема
. При нарушении условия (5) в списке появляется еще одна, (R+1)-я фонема 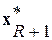 .
.
Вычисления по схеме (3…5) повторяются циклически для всех последующих сегментов данных из речевого сигнала X, причем повторятся «нарастающим итогом» для переменного значения R=1, 2,… В результате получим множество из R* выявленных на первом этапе обработки фонем. При этом понятно, что с точки зрения качества полученного результата первостепенный интерес представляет собой множество четких фонем. Поэтому в работе [8] была предложена дополнительная процедура отбраковки сомнительных по своей четкости фонем путем установления к ним требования по минимальной длительности эталонных ЭРЕ вида
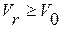 (6)
(6)
Здесь 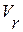 - число отсчетов в векторе r-й фонемы
- число отсчетов в векторе r-й фонемы 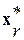 ;
; 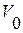 – пороговый уровень для минимального числа отсчетов в результирующем списке фонем. Множество R<R* четких фонем и следует считать, в общем случае, основным результатом фонетического анализа речи на первом этапе обработки речевого сигнала.
– пороговый уровень для минимального числа отсчетов в результирующем списке фонем. Множество R<R* четких фонем и следует считать, в общем случае, основным результатом фонетического анализа речи на первом этапе обработки речевого сигнала.
Его наиболее полная информационная характеристика – это (R 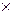 R)-матрица
R)-матрица 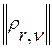 величин ИР
величин ИР 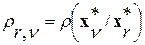 между всеми парами выявленных фонем. В качестве примера в табл. 1 представлен фрагмент такой матрицы для случая R =20, полученной экспериментальным путем в условиях и с применением программных средств из упомянутой выше работы [8] для одного диктора-мужчины при установленных в алгоритме (3…5) порогах
между всеми парами выявленных фонем. В качестве примера в табл. 1 представлен фрагмент такой матрицы для случая R =20, полученной экспериментальным путем в условиях и с применением программных средств из упомянутой выше работы [8] для одного диктора-мужчины при установленных в алгоритме (3…5) порогах 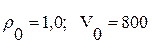 .
.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|