- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
СОДЕРЖАНИЕ 5 страница

|
| Особый алгоритм имеют и злостные безбилетники, но их алгоритм, однако, нельзя назвать эффективным |

|
| РИС. 6 |
Существует большое число тестов, которые подтверждают эту особенность человеческого восприятия — видеть не то, что показывают, а по привычке что-то другое. Проведем эксперимент. Вспомним замечательное пушкинское произведение “Пиковая дама”. Умозрительно выберем два персонажа: Лизу и графиню, которая скрывала тайну трех карт. Теперь внимание! Вы должны решить для себя вопрос: кого вам хотелось бы увидеть сейчас — девушку или старуху? Если вы такой выбор сделали, посмотрите на рис. 6. Кого же вы увидели? Авторы этой книги неоднократно проводили этот эксперимент с учащимися курсов быстрого чтения и убедились, что чаще всего привычным, предпочтительным желанием увидеть определенный персонаж и предопределялось фактическое восприятие образа с рисунка. А на рис. 6 изображен тест из серии так называемых картин с конкурирующими образами, где одновременно увидеть два лица невозможно, но они там изображены. И только после длительного рассмотрения удается увидеть и второй образ, а по первому впечатлению вы видите то, на что настроились.
Исследователи теории установки утверждают, что путем многократных повторений установка превращается в устойчивый стереотип на уровне активной автоматизированной деятельности. Человек приобретает определенную систему привычек и навыков, которую затем легко использует автоматически, без напряжения ума.
Наши наблюдения показали, что при использовании интегрального алгоритма чтения формируется навык чтения, предусматривающий определенную последовательность рациональных действий в соответствии с блоками алгоритма от первого до последнего. Образец интегрального алгоритма показан на рис. 7.

|
| РИС 7 |
Первые четыре блока алгоритма пояснять не надо. Пятый блок — фактографические данные — означает извлечение фактов из текста и смысловое их усвоение. Особенность шестого и седьмого блоков алгоритма в том, что оба они предполагают учет индивидуальных особенностей читателя: его знаний, опыта, цели чтения. Например, то, что одному читателю кажется тривиальным, другому, менее опытному, покажется новым, а критически настроенному читателю — спорным. Таким образом, эти оба блока предполагают активное участие читателя в выполнении сложных аналитико-синтетических мыслительных действий в процессе чтения.
Как же практически пользоваться этим алгоритмом? Прежде всего необходимо запомнить все его блоки, представлять себе их заполнение содержанием. По ходу чтения текста мы рекомендовали учащимся нарисовать алгоритм на отдельном листе бумаги и укрепить его над рабочим столом для лучшего усвоения. В самом деле, как мы читаем? “Как придется”, - отвечают некоторые, а большая часть людей вообще никогда не задумывалась над этим. Чтение по интегральному алгоритму - это организованный и целеустремленный процесс, в ходе которого считываемая информация как бы выбирается из текста и сопоставляется с отдельными ячейками - блоками алгоритма. В случае полного или частичного соответствия информация как бы укладывается в них. Процесс такого чтения можно сравнить с отбором товара в универсаме. Представьте: вы везете перед собой тележку с семью ячейками и в соответствии с имеющейся у вас запиской - поручением от домашних - быстро отбираете нужный товар. Теперь допустим, что по дороге записка потерялась. Вы мучительно вспоминаете о пунктах поручения и бесцельно блуждаете по торговому залу, как в лабиринте, в надежде, что, увидев нужные предметы, вспомните о том, что необходимо купить. Большинство читателей подобны именно такому покупателю, потерявшему записку - этот спасительный алгоритм умственных действий.
|
| Вы мучительно вспоминаете о пунктах поручения и бесцельно блуждаете по торговому залу, как в лабиринте, в надежде, что, увидев нужные предметы, вспомните о том, что необходимо купить |
Есть и еще один существенный довод в пользу применения алгоритма. Современная структурная лингвистика утверждает, что научно-технические тексты обладают избыточностью, которая достигает порой 75% . Практически только 25% объема текста несут основной смысл для конкретного читателя и данного вида чтения. Умению найти и сосредоточить внимание при чтении на обработке только этого содержательного объема текста и помогает интегральный алгоритм. При его использовании значительно сокращается время перебора неинформативных элементов текста и, наоборот, более эффективно читается его содержательная часть. Здесь всегда реализуется атвоматическое чтение с переменной скоростью: “пустые места” читаются на большей скорости, чем содержательная часть текста, имеющая конкретное значение.
Для практического освоения алгоритма большое значение имеет образное его представление. Каждый из читателей может разработать свою схему — образ зрительного представления алгоритма. Тем самым читатель будет решать задачу не только алгоритмизации усвоения текста, но и развития навыка использования предметно-изобразительного кода, который значительно эффективнее других видов кодов переработки информации при чтении.
Как же вырабатывается установка на чтение с применением алгоритма? Перед началом чтения нужно зрительно представить себе блоки алгоритма. Прежде всего запоминаются блоки: название, автор, выпускные (выходные) данные источника. Затем по мере чтения складывается представление о том, какой проблеме посвящена статья; это войдет в четвертый блок — основное содержание, тема. Уже в первых абзацах текста могут быть различные факты, фамилии, параметрические данные. Все эти сведения фиксируются в пятом блоке алгоритма.
В процессе чтения текста читатель как бы фильтрует его содержание, отбирая и укладывая в блоки алгоритма только то, что соответствует названиям блоков. Вот, например, в тексте описывается конструкция нового электроавтомобиля, имеющего принципиальные отличительные особенности. Внимание! Это материал для заполнения шестого блока. Очень важно при чтении быть критически настроенным к содержанию текста. Как считают некоторые психологи, без критического отношения вообще читать не следует. Ваша позиция — согласие или несогласие с автором — также фиксируется в этом блоке алгоритма. Наконец вы закончили чтение. Что нового вы узнали из прочитанного, что можно практически применить в своей работе? Это данные для заполнения последнего, седьмого блока алгоритма.
Итак, чтение окончено? Для обычного, традиционного чтения может быть и так. Для быстрого чтения этого еще недостаточно. Завершение чтения еще впереди. Закончив чтение, читатель должен вновь представить зрительный образ интегрального алгоритма и проверить достаточность заполнения всех его блоков. Такой заключительный психологический акт анализа и синтеза текста помогает лучше его усвоить и запомнить. Психологи говорят: “Умей ставить точку”.

|
| Пример зрительного представления интегрального алгоритма чтения 1. Название. 2. Автор. 3. Выходные сведения. 4. Основная идея. 5. Фанты. 6. Критика. 7. Новизна |
Очевидно, именно этот прием объясняет то, что читающие быстро лучше, полнее усваивают и запоминают прочитанное, чем те, кто читает медленно и главное неумело. Как показывает наш опыт, зрительное представление блоков интегрального алгоритма чтения значительно облегчает решение этой задачи.
На одной из лекций о технике быстрого чтения в Центральном лектории Всесоюзного общества “Знание” в Москве инженер А. Агеев прислал записку, в которой написал: “Интегральный алгоритм — это основа метода быстрого чтения. Я употребляю свой зрительный образ, связанный с запуском космического корабля: 1. Название корабля. 2. Экипаж корабля. 3. Дата запуска, место и время. 4. Программа полета. 5. Факты, полученные во время полета. 6. Особенности данного полета. 7. Что нового дал полет? Вначале у меня всегда при чтении возникал образ стартовой площадки запуска космического корабля и считываемая информация укладывалась в блоки алгоритма, как в ступени космического корабля. Затем, после двух недель тренировок, я с удивлением обнаружил, что зрительное представление интегрального алгоритма как бы поблекло, стерлось. Но по окончании чтения очередного текста, пытаясь вспомнить все, что только что прочел, я убеждался, что нужные мне данные всплывали автоматически, как бы сами собой. Я затем всегда мог ответить на любой вопрос в соответствии с блоками алгоритма”.
Наблюдения показали, что для освоения интегрального алгоритма указанный порядок тренировок очень эффективен. Вначале держат рисунок с изображением алгоритма перед собой и читают текст. Задача такого чтения — извлекать из текста только такую информацию, которая соответствует блокам интегрального алгоритма чтения. В процессе последующих тренировок вырабатывается автоматизм при фильтрации текста. Затем формируется и закрепляется только такое чтение.
Вместе с тем интегральный алгоритм чтения способствует подавлению еще одной вредной привычки — регрессии. Организованное, активное чтение в соответствии с блоками алгоритма заставляет читателя при однократном чтении хорошо понимать и усваивать текст. Непрерывное следование блокам интегрального алгоритма чтения, динамизм мыслительных процессов уже не оставляют времени для повторных возвратов глаз. Неуверенность, которая возникает вначале из-за боязни упустить что-то важное, ценное, сменяется затем убежденностью, что однократного чтения достаточно для глубокого усвоения прочитанного.
Для отработки устойчивого навыка такого чтения и его закрепления разработано основное правило чтения: текст любой трудности всегда читается только один раз. Возвратные движения глаз недопустимы. Только по окончании чтения и осмысления прочитанного можно вернуться к повторному чтению, если возникла необходимость в этом.
ГЛАВА ЧЕТВЕРТАЯ ПОНИМАНИЕ ПРОЧИТАННОГО
ПРИЕМЫ ОСМЫСЛЕНИЯ ТЕКСТА
Понимание прочитанного — непременное условие эффективного чтения. Быстрое чтение выдвигает проблему понимания текста на первое место.
Что же такое понимание? Психологи называют пониманием установление логической связи между предметами путем использования имеющихся знаний. При чтении несложного текста понимание как бы сливается с восприятием — мы мгновенно вспоминаем полученные ранее знания (осознаем известное значение слов) или отбираем из имеющихся знаний нужные в данный момент и связываем их с новыми впечатлениями. Но очень часто при чтении незнакомого и трудного текста осмысление предмета (применение знаний и установление новых логических связей представляет собой сложный развертывающийся во времени процесс.
Как указывает проф. Л. П. Доблаев, для осмысления текста в таких случаях необходимо не только быть внимательным при чтении, иметь знания и уметь их применять, но и владеть определенными мыслительными приемами. Изучая процессы запоминания, проф. А. А. Смирнов также установил, что при необходимости запомнить текст ,человек вначале старается лучше понять его и применяет для этого различные приемы. Чаще всего читатели используют три основных приема: выделение смысловых опорных пунктов, антиципацию и реципацию.
Деление текста на части, его смысловая группировка и приводят к вы делению смысловых опорных пунктов, углубляющих понимание и облегчающих последующее запоминание материала. Психологи выяснили, что опорой понимания может быть все, с чем мы связываем то, что запоминается, или что само “всплывает” как связанное с ним. Любая ассоциация может быть в этом смысле опорой. Смысловой опорный пункт есть именно пункт, как бы некоторая точка, т. е. нечто краткое, сжатое, но в то же время служа; идее опорой какого-то более широкого содержания. Понимание сводится к тому, чтобы схватить в тексте основные идеи, значимые слова, короткие1 Фразы, которые предопределяют текст последующих страниц. Свести содержание текста к коротким и существенным логическим формулам, отметить в каждой формуле центральное по смыслу понятие, ассоциировать эти понятия между собой и образовать таким путем единую логическую цепь идей — вот сущность понимания текста. Прием выделения смысловых опорных пунктов представляет собой как бы процесс фильтрации и сжатия текста без потери основы.
С помощью этого приема нами разработан дифференциальный алгоритм чтения, который будет подробно рассмотрен ниже.
Другой прием, используемый для дальнейшего осмысления читаемого текста, называется антиципацией, или предвосхищением, т. е. смысловой догадкой. Квалифицированный читатель по нескольким начальным буквам угадывает слово, а по нескольким словам — фразу, по нескольким фразам — смысл целого абзаца или даже страницы. Это происходит потому, что мышление активно работает в продуктивном режиме. При таком чтении читатель в большей степени опирается на содержание текста в целом, чем на значение отдельных слов. Главное — это осмысление идеи содержания, выявление основного замысла автора текста.
Поскольку есть прямая зависимость между вероятностным прогнозированием графического шрифтового материала и частотой встречаемости его в текстах, нас в первую очередь интересуют условия, при которых одни и те же обороты речи, фразы, слова повторяются наиболее часто. Эффективное управление процессом антиципации зиждится на понимании стереотипности текстов.
Явление антиципации закономерно, и оно в значительной степени объясняется избыточностью текста, составляющей, как мы уже знаем, 75% . Существуют несложные тексты, которые Позволяют оценить способность читателя к антиципации. В приложении 4 приведен такой текст.. Читая его и выполняя задание, читатель получит количественное представление о своих способностях в этом виде деятельности.
При обучении быстрому чтению с учетом способности антиципировать основным фактором является формирование своеобразного чутья к фразовым стереотипам и накопление достаточного словаря текстовых штампов. Выявление фразовых стереотипов — одна из первых предпосылок для выработки автоматизма рецептивной обработки текста. В результате выявления многократных повторений текстовых штампов и воспитывается навык антиципации. .
Последний прием, который мы рассмотрим, называется реципацией, или мысленным возвратом к прочитанному под влиянием новых мыслей, возникших в процессе чтения. Этот прием следует отличать от регрессий. Регрессии —механические непроизвольные повторы, и они не способствуют лучшему пониманию. Однако очень часто, прочитав какое-то положение и продолжая чтение, читатель мысленно возвращается к предыдущим высказываниям автора, связывая их с новыми, изучаемыми в данный момент. Такой мысленный возврат способствует более глубокому пониманию изучаемого текста.
ФИЛЬТРУЮЩАЯ СПОСОБНОСТЬ МОЗГА
Рассмотренные нами три приема понимания текста интуитивно использует большинство читателей. Однако, как показали эксперименты Л. П. Доблаева[14], целенаправленное обучение этим приемам значительно повышает продуктивность осмысления различных текстов.
Проведенный краткий разбор этих приемов показывает сложность и комплексность процесса мышления и восприятия любого текста. При быстром чтении понимание текста носит активный и свернутый характер и использование рассмотренных выше приемов осмысления безусловно полезно.
Рассмотрим теперь некоторые особенности процесса понимания более подробно. При этом, как и ранее, будем опираться на известные науке закономерности работы мозга.
Понимание — один из результатов умственной деятельности. Если человеческое мышление — это переработка полученной информации, то понимание определяет полноту и эффективность этой переработки. Мало только увидеть какой-либо предмет. Осмыслить его содержание и осознать назначение — вот конечная задача человека. Эта особенность известна давно. У крупнейшего австрийского поэта Р. М. Рильке мы находим такие строки:
...Зренье свой мир сотворило,
Сердце пускай творит из картин,
Заключенных в тебе, ибо ты
Одолел их, но ты их не знаешь...
В этих строках можно увидеть модель усвоения информации человеком, если слово “сердце” заменить словом “мозг”. В самом деле, мозг человека — хранилище разнообразной информации, накопленной в результате опыта и обучения. Этой информацией человек пользуется в течение всей жизни. Каждую секунду он извлекает из этого гигантского хранилища нужные сведения. И при чтении текста человек не только получает новую информацию, но и извлекает из глубин памяти уже имеющуюся.
В коре головного мозга сливаются как бы два потока информации: внешней и внутренней. Как же происходит их последующая обработка? Мы уже знаем, что в основе работы головного мозга лежит взаимодействие различных структур коры больших полушарий, — правого и левого. Мозг фильтрует информацию, сжимает ее, освобождая от излишней.
Хотя этот механизм еще не до конца изучен, уже сейчас можно предположить, что в мозге человека есть специальный алгоритмический фильтр, который при чтении текста пропускает для дальнейшей обработки только осмысленные словосочетания. Эта закономерность работы мозга была установлена проф. Н. И. Жинкиным, наблюдавшим со своими коллегами случаи расстройства речи ребенка.
Однажды в клинику поступила девочка Алла С. 9 лет с диагнозом: расстройство речи. Алла хорошо понимала значение отдельных слов, но когда ее просили оценить смысл простых предложений, она терялась и путала простейшие грамматические конструкции. Например, ее спрашивали, можно ли сказать: “Суп из гороха”? Она отвечала: “Можно”. Но и на вопрос о том, можно ли сказать “Чулки из камня, суп из чулок, чулки из супа” и т. п. она тоже ответила утвердительно, явно не понимая бессмысленности этих предложений. Как установили, у Аллы возникло заболевание, которое называется “грамматическая афазия”, или “смысловая глухота”. Выражаясь образно, у нее в смысловом фильтре образовались большие дыры, через которые проникали бессмысленные словосочетания. Алла не воспринимала смысла слов и поэтому понимала обращенную к ней речь пассивно, механически. Слова не привлекали ее внимания. Для нее все равно — чулки из ниток или чулки из супа. При этом она хорошо знает, что означают отдельные слова “нитки”, “чулки”, “суп”. Она органически не могла конструировать смысловые ряды — пары значимых слов.
После выяснения природы заболевания девочка была успешно излечена, а анализ заболевания дал интересный материал для разработки проблемы “грамматика и смысл”. Как установил Н. И. Жинкин в ходе этого исследования, на стадии обработки поступающей информации в человеческом мозге есть специальный функциональный алгоритмический фильтр, который не пропускает для дальнейшей обработки бессмысленные словосочетания. Пока никто еще не измерил эффективности использования этого тонкого механизма в человеческом мышлении. Однако есть основания полагать, что потенциальные возможности этого фильтра большинство людей использует очень слабо. При чтении человек должен мгновенно оценить смысловую сторону сообщения и наметить пути дальнейшей его обработки. Причем характерно, что формальная грамматика текста данного языка не имеет существенного значения для восприятия смысла. Так, если составить бессмысленную фразу, хотя грамматически и правильную, то она не будет обрабатываться. Например: “Зеленые идеи яростно спят”. И наоборот, словосочетание, даже построенное с нарушением грамматических норм, но легко поддающееся осмыслению, мозгом воспринимается и обрабатывается успешно. Например: “Моя твоя не понимай”.
Это обстоятельство было отмечено и выдающимся советским психологом Л. С. Выготским, который говорил, что необходимо уметь различать законы развития смысловой стороны речи и ее внешнего физического оформления, выражающегося в правилах построения предложений, правил грамматики и т. п. То, что с точки зрения грамматики языка является ошибкой, “может иметь психологическую ценность на уровне мышления”. В доказательство этого он приводил пушкинские строки:
Как уст румяных без улыбки,
Без грамматической ошибки
Я русской речи не люблю.
|
| Суп из чулок, чулки из супа |
Знаменитое чеховское предложение: “Подъезжая к сией станции... у меня слетела шляпа”, — также дает пример такого психологически понятного, но грамматически неправильного предложения.
Из сказанного следует, что для развитого взрослого человека естественно использовать более информативный язык, хотя иногда и в ущерб строгим грамматическим правилам. Однако это последнее утверждение вовсе не отрицает необходимости самого глубокого изучения грамматики. Исследования, проведенные в последние годы, показали, что линейность внешней речи, фиксируемой в текстах, не доказывает линейного восприятия текста по принципу “слева направо” и элемент за элементом. Как убедительно доказали Д. Миллер, Ю. Галантер и К. Прибрам, “для того, чтобы ребенок обучился всем правилам этой грамматической последовательности ... он должен был бы выслушать приблизительно 3020 предложений в секунду, для того чтобы воспринять всю информацию, необходимую для формирования грамотного предложения”[15]
Рассмотренная закономерность работы мозга объясняет и тот факт, что человек в любом, даже, казалось бы, в самом бессмысленном, выражении: пытается отыскать смысл. Здесь можно напомнить читателям об известном психологическом эксперименте академика Л. Щербы. На одной из лекций по языкознанию он предложил студентам изложить содержание следующей фразы: “Глокая куздра штеко будланула бокра и курдячит бокренка”.
Несмотря на кажущуюся бессмысленность этого предложения, большинство студентов нашли, что в этой фразе говорится о том, что какое-то существо женского пола “наподдало” другому существу мужского пола и продолжает те же действия по отношению к его детенышу. Мы также повторили этот опыт. В одном из наших экспериментов предложили испытуемым следующую фразу: “Швыдкая чурла незденко сигла по донку и одвырла чурта с чурятами”.
И в этом случае большинство испытуемых правильно осмыслили структуру этого текста.
Еще более интересный факт приводит проф. А. А. Реформатский в одной из последних своих работ, которая называется — “Компрессивно-аллегровая речь”: “Мы заметили, что часто, выйдя из нашего домика, Ф. И. Шаляпин... громким раскатистым басом что-то кричал на всю улицу. Слов мы понять не могли, и нам слышалось лишь:
— В-о-о!
После этого странною возгласа со всех концов съезжались таратайки...” Далее А. А. Реформатский пишет: “Как же извозчик в этом „В-о-о!” смог опознать слово „извозчик”? Ведь тут и слоговость не та, и нет ни головы, ни хвоста, да еще такого „характерного” для русского языка, как ,,-щик”... остался только один ударный двухфонемный слог, и это не корень, не основа. А все-таки извозчик приехал. Он услышал и понял. “ ... ” В этом, собственно, и содержится секрет компрессивно-аллегровой речи. А понял извозчик потому, что этого возгласа, где остальное „компрессировано”, достаточно для речевого общения благодаря известности ситуации речи.

|
| Человек в любом, даже, казалось бы, в самом бессмысленном выражении пытается отыскать смысл |
Данный случай — исключительный и даже не вполне точно отвечающий данным параметрам явления. Но очень показательный и убедительный. В нашем ежедневном речевом общении мы постоянно пользуемся этой компрессивно-аллегровой манерой, и это безусловно интересный факт лингвистики речи”.
В самом общем случае можно сказать, что живой язык стремится свести к минимуму усилия акта коммуникации: пишем четыре, а говорим “четые”, пишем “пожалуйста”, а говорим “пожалста”. Этот принцип реализуется не только в речи, но и при чтении — это необходимо знать и уметь использовать при быстром чтении.
ДЕНОТАТ - ЗНАЧЕНИЕ И СМЫСЛ
О чем говорят разобранные примеры? Они свидетельствуют о том, что осмысление текста — это сложный процесс. Вместе с тем он подчиняется определенным законам, обусловленным феноменальными особенностями работы человеческого мозга. Как же использовать эти законы для нашей задачи: научиться при быстром чтении глубоко и полно понимать текст? Чтобы найти пути решения этой проблемы, необходимо вначале решить вопрос о том, что следует понимать в читаемом тексте? Очевидно, некоторым читателям сам вопрос может показаться бессмысленным: ясно — все, что содержится в нем. И вот здесь нас ожидает интересное открытие: текст весь, целиком читать не надо. Чтобы понять его, достаточно прочесть только некоторую его часть, которую можно условно назвать “золотым ядром” содержания.
Это именно те 25% содержания текста, которые остаются после исключения избыточности.
Что же представляет собой “ядро”? Чтобы понять это, рассмотрим основные семантические принципы построения текста. Как установила современная лингвистика, тексты обладают единством внутренней логической организации. Они строятся по единым логическим правилам связности изложения. Кроме того, как мы уже знаем, избыточность текстов весьма велика и доходит до 75% . Очевидно, “золотое ядро”, о котором мы говорим, и несет основную смысловую нагрузку. А если это так, то целевой процесс преобразования текста на сжатие при чтении можно условно считать выделением и формированием этого “ядра”. На рис. 8 приведена блок-схема последовательности выполнения этой операции. Текст содержит определенную информацию, которую читатель в нем видит. Таким образом, первый шаг на пути преобразования текста — выделение интересующей информации. Здесь под информацией мы понимаем то, что данный текст передает конкретному читателю.
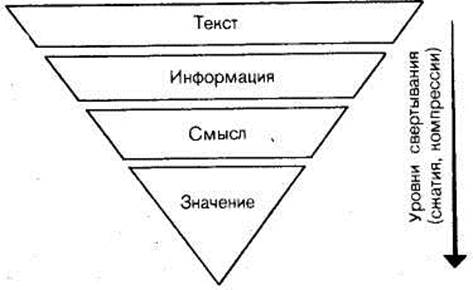
|
| РИС. 8 |
Будем исходить при описании дальнейших преобразований из семантической теории информации, разработанной советским математиком и лингвистом Ю. А. Шрейдером. Согласно этой теории, читатель, изучай информацию, сравнивает ее с тем объемом знаний (тезаурусом), которым он располагает в данный момент. В результате такого сравнения читатель дает оценку поступающей информации. Это означает, что если вначале читатель не понял текста, то текст не несет для него никакой информации, Если затем, спустя даже длительное время, получив новые знания, читатель вторично обращается к этому же тексту, то на этот раз он уже извлекает из него нужную информацию. Что же происходит с ней дальше? В результате изучения текста читатель выделяет смысл, который преобразуется затем в значение. Здесь мы ввели два новых термина и, прежде чем разбирать сущность происходящего далее процесса, необходимо дать им объяснение. Что же такое смысл и значение? Впервые изучение понятий “смысл” и “значение” предпринял известный немецкий математик и логик Готлоб Фреге.
В 1892 г. вышла его работа “О смысле и значении”, которая до настоящего времени не потеряла своей актуальности и по-прежнему популярна среди математиков, лингвистов и логиков.
Г. Фреге определяет смысл как содержание языкового выражения, т. е. это мысль, содержащаяся в словах. Значением языкового выражения является тот сущностный предмет, который словесно зафиксирован в сознании человека. Например, значением слова “Луна” по существу является определенное небесное тело или естественный спутник Земли, вращающийся вокруг нее и видимый нами каждую ночь.
Согласно концепции Г. Фреге, отношение имени к тому, что оно называет или обозначает, является отношением называния, а вещь, которая называется, является значением этого имени. Всякое имя всегда что-то называет (это функция номинации) и это что-то — определенная вещь. Естественно, что могут быть и неназванные вещи.
Таким образом, значение — это сущностное свойство имени, которое реализуется путем многообразного называния вещей. Смыслом Г. Фреге называет различие в способе формального обозначения предметов именами. Имена типа: “А. Пушкин”, “Великий русский поэт”, “Поэт, убитый Дантесом” — различны по смыслу, но одинаковы по значению. В текстах можно найти разные способы использования имен: педагог — преподаватель; врач — доктор; разведчик — шпион и т. д. Эти примеры сообщают разные сведения об одном и том же предмете. Таким образом, смысл имени есть то, что передается и понимается в сообщении как социально значимая информация и что при приеме сообщения должно быть понято однозначно. Два выражения могут иметь одно и то же значение, но разный смысл, если эти выражения различаются по структуре реализации текста. Например, рассмотрим выражения: “5” и “3 + 2”.
Смысл в каждом из них различный, а значение и в первом и во втором одинаковое.
Теперь вновь обратимся к рис. 25. Заключительные этапы преобразования фрагмента текста включают выделение из полученного смысла значения. Означает ли это, что всегда, в любом тексте есть все компоненты этой схемы? Совсем нет. Однако вероятность наличия каждого ее элемента идет по убывающей. В самом деле, тексты всегда содержат информацию. Немного можно найти бессмысленных текстов. Но очень много текстов осмысленных и тем не менее не содержащих значения. В литературе по логике обычно приводят пример такого пустого выражения. Понятие, выраженное словами “король Франции”, имеет смысл, но применительно к XX в. значения не имеет. Возможны ли научные тексты подобного содержания?
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|