- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Writeln(UTF8ToConsole(‘привет’))
В Lazarus существует проблема при работе с русским языком. Дело в том, что в кодировке ASCIIкаждый символ занимает 1 символ. Однако в современных операционных системах используется Юникод. Изначально (в 1991 году) был изобретён Юникод, в котором каждый символ кодировался 2 байтами UTF-16 (что означает 16 бит). Оказалось, что данная кодировка не позволяет кодировать все возможные символы всех языков. В настоящее время самая распространённая кодировка UTF-8. Это неравномерный код. Символы, которые в ASCII кодировке были в первой странице (с кодом до 127), занимают 1 байт (старший бит равен 0), остальные кодируются кодом переменной длины от 2 до 6 байт, при этом старший бит первого символа устанавливается в 1.
При работе в консольном режиме текст, вводимый с клавиатуры и выводимый на экран, кодируется в кодировке ASCII, а в тексте программы используется кодировка UTF-8. Также в LCL-приложениях (работа с формами) используется UTF-8 кодировка.
Для корректной работы с русским языком необходимо подключить соответствующий пакет.
Для этого в пункте «Проект» выбрать пункт «Инспектор проекта»



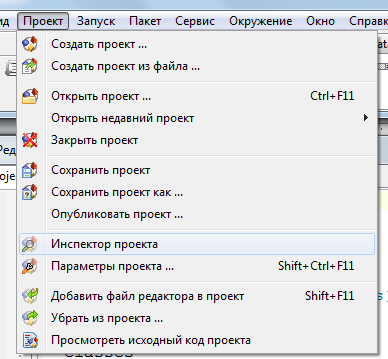
В появившемся окне нажать кнопку «+»

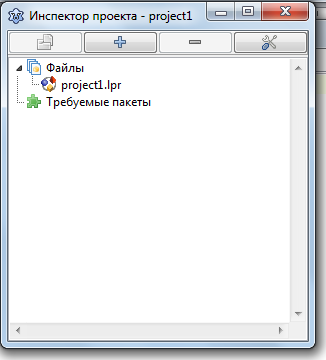
Выбрать вкладку «Новая зависимость»

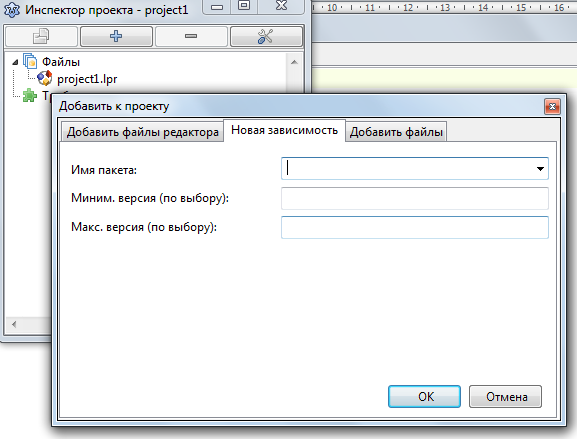
В поле «Имя пакета» выбрать LCL

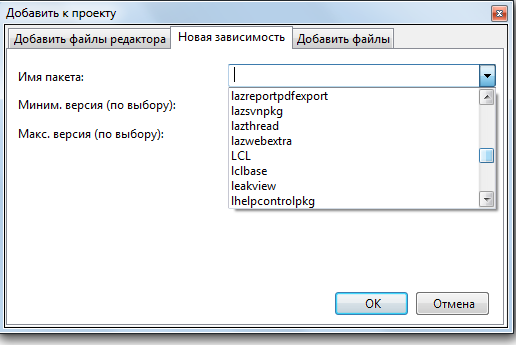
После нажатия кнопки «Ок» в списке «Требуемые пакеты» появится пакет LCL.

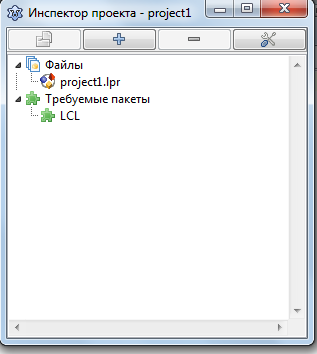
После нажатия кнопки «Ок» в списке «Требуемые пакеты» появится пакет LCL.
Кроме того, необходимо добавить модули FileUtilиLCLProc (в разделе Uses).
Для того, чтобы вывести на экран (в консольном приложении) русский текст, необходимо перекодировать текст, используя функцию UTF8ToConsole()
Пример
Writeln(UTF8ToConsole(‘привет’))
И, наоборот, если необходимо ввести текст с клавиатуры, то используется функция ConsoleToUTF8()
Пример
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|