- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
План шестого занятия по статистическому практикуму.
1. Нелинейная регрессия. К нелинейной регрессии можно прибегать в ситуациях, когда имеющиеся данные плохо описываются линейными методами. При этом исследователь должен самостоятельно выбрать семейство функций, по которым проводится регрессия, и также в ряде случаев задать их параметры.
Открыть файл «Нелинейные». Строим точечную диаграмму первых двух столбцов. Добавляем линейную линию тренда (с выводом графика и коэффициента R2). Получаем коэффициент детерминации 0. 97. Следует отметить, что в другой ситуации это значение можно было бы рассматривать как хорошее объяснение, если бы отклонения от прямой выглядели бы случайными. Но в данном случае четко видно, что мы имеем не случайные отклонения, а именно другую форму кривой, выпуклую вверх. В частности, если нас попросят «предсказать» дальнейшее поведение кривой, то никто не воспользуется для этого построенной прямой.
Попробуем использовать более сложное семейство, а именно – полиномы второй степени (оно, в частности, включает в себя и линейные функции). Для этого кликаем правой клавишей мыши на линии тренда, входим в свойства и корректируем их. Выбираем полиномиальное семейство и степень 2. Получается теперь уже коэффициент 0. 99 и теперь уже наблюдаемые отклонения от построенной линии выглядят случайными. Но можно отметить, что я бы не стал утверждать, что дальнейшее поведение построенной линии будет хорошо соответствовать наблюдениям. У меня лично есть визуальное ощущение, что линия все равно пройдет высоковато.
Я рекомендую также провести еще один эксперимент. У нас всего 6 точек. Попробуем еще раз зайти в свойства тренда и поставить степень 5. Значение R2 теперь стало ровно 1, что легко объяснить математически, так как мы имеем 6 свободных коэффициентов (переменных), с помощью которых можно просто точно провести линию через все имеющиеся точки. Но видно, что получилось нечто странное: линия меняет выпуклость, а также ее последующее поведение совсем не соответствует ожидаемому. Для наглядности можно еще раз зайти в свойства тренда и поставить прогноз на 0. 5 шага вперед. Получается полное расхождение с тем, что мы ожидаем.
Надо объяснить, что неправильно неограниченно увеличивать число степеней свободы того семейства функций, которое мы используем для регрессии. Тем самым мы можем лучше приблизить имеющиеся у нас точки, но реально мы начиная с какого-то момента начинаем использовать наши степени свободы для приближения не существенных закономерностей, а случайных отклонений. Поэтому нужно стараться обойтись минимальным числом степеней свободы, которое возможно.
В первой части задания «Нелинейная регрессия» нужно подобрать наилучшее приближение из трех предлагаемых – параболическая, степенная или экспоненциальная. Следует построить все три аппроксимации и затем сформулировать вывод о том, какая лучше всего.
2. Открыть файл «Адсорбция». Два вида формул могут описывать данные:
1. 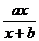 - обращенный полином 1-ой степени - изотерма Лэнгмюра.
- обращенный полином 1-ой степени - изотерма Лэнгмюра.
2. 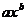 - степенная,
- степенная, 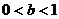 . - изотерма Фрейндлиха.
. - изотерма Фрейндлиха.
Рассматриваем азот (столбцы C-D). Можно построить диаграмму и наложить на нее линию степенного тренда. Видно, что она плохо ложится, значение R2 = 0. 96. Но изотермы второго вида в Excel нет.
Применим AtteStat. Запускаем AtteStat -> Аппроксимация зависимостей. Интервал абсцисс C3: C10, интервал ординат D3: D10, интервал вывода решения A27, тип зависимости – степенная. Выполняем расчет. Коэффициенты зависимости должны получиться те же, что и на диаграмме. Величина коэффициента детерминации равна 0. 87, это некоторая другая характеристика того, насколько «хорошее» получилось приближение.
Теперь попробуем изотерму Лэнгмюра. Заметим, что такого рода зависимости не реализовано в пакете, поэтому нам придется применить некоторые преобразования. А именно, 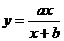 перепишем в виде
перепишем в виде 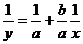 , и таким образом мы нелинейную регрессию свели к линейной относительно переменных
, и таким образом мы нелинейную регрессию свели к линейной относительно переменных  и
и  .
.
Итак, в ячейку J3 вводим формулу =1/С3 и протягиваем ее до ячейки С10. В ячейку K3 вводим формулу =1/D3 и протягиваем ее до ячейки D10.
Снова запускаем AtteStat -> Аппроксимация зависимостей. Интервалы абсцисс J3: J10 и ординат K3: K10, выходной интервал E27, тип – линейная. Получаем значение коэффициента детерминации 0. 99, т. е. указанные данные описываются именно этой изотермой.
Во второй части задания нужно провести те же действия и написать вывод о том, какой тип изотермы лучше описывает их данные.
3. Теперь переходим к последней части задания " Многомерный анализ". Мы будем решать задачу дискриминантного анализа, т. е. отнесения наблюдаемых объектов в одну из нескольких известных групп. Каждый объект представляет собой числовой вектор, состоящий из нескольких характеристик, измеренных у этого объекта. Для решения задачи должен быть задан т. н. обучающий набор, т. е. набор объектов, про которые известно, к какому классу они принадлежат. Программа будет стараться подобрать такие критерии, по которым объекты этого набора будут правильно классифицироваться. Этот процесс называется " обучением". Когда критерии настроены (система обучена), то их можно использовать для классификации новых объектов.
Существует множество разных типов критериев. Мы будем использовать самые простые, при которых строятся линейные разделяющие поверхности для разных групп. На самом деле, этот способ является оптимальным в случае, например, когда в каждой группе наблюдения распределены по многомерному нормальному закону.
Открываем файл " Молоко-1". Мы видим таблицу, в которой приведены (средние) значения некоторых характеристик, которые можно измерить у пробы молока, а в столбце I - номер группы, к которой относится соответствующее молоко.
Одна из первых задач - это отбор из множества характеристик небольшого количества тех, которые будут использоваться для работы. Их количество должно быть существенно меньше, чем количество элементов в обучающем наборе. Иначе возникает похожая ситуация, которую мы наблюдали с нелинейной регрессией: если число переменных слишком велико, то программа без труда настроит правило, которое будет точно классифицировать именно этот обучающий набор, однако при работе с новыми наблюдениями будут большие ошибки.
Сейчас мы не будем проводить подбор параметров, а будем использовать столбцы C и D - содержания кальция и фосфора. Но в заданиях подбор нужно будет проводить, как - будет показано позже. Сейчас, поскольку у нас две переменных, то мы построим диаграмму рассеяния на плоскости, на которой " увидим" рассматриваемые группы и поймем, можно ли их потенциально различить тем методом, который мы собираемся использовать.
Для этого запускаем мастер построения диаграмм, выбираем точечную диаграмму и создаем три ряда данных: первый соответствует группе 1 (X = C3: C8, Y = D3: D8, выбирать мышью, так как ручной ввод почему-то выдает ошибку), группа 2 (C11: C19, D11: D19) и группа 3 (C9: C10, D9: D10). Видно, что хотя облака не очень хорошо выражены и наглядны, но тем не менее, линейно разделить их можно.
В самостоятельной работе дано 60 наблюдений, разбитых на три группы (по 20 в каждой). Каждое наблюдение характеризуется тремя параметрами. Требуется (аналогично тому, как было сделано в задании Корреляции) рассмотреть три случая, соответствующих трем возможным способам выбора двух переменных (AB, AC и BC). Для каждого случая нужно будет построить подобную диаграмму и выбрать такие две переменные, при которых группы разделяются лучшим образом.
Теперь введем новую точку: в ячейку C20 поместим значение 120, а в ячейку D20 - значение 110. Добавим это значение на диаграмму в качестве четвертого ряда (правой клавишей мыши по диаграмме, найти данные, добавить еще одну серию). Видно, что новая точка попадает в середину первой группы, так что решение должно быть именно таким. Проверим это.
Запускаем AtteStat -> Распознавание образов. Первая вкладка " Обучение". Интервал обучающей выборки: C3: D19. Интервал номеров классов: I3: I19. Интервал вывода результатов: A33. Метод распознавания - линейный дискриминантный анализ Фишера. Выполнить расчет.
Программа выводит некоторую общую информацию (полезную для проверки того, что все данные введены правильно): общая численность выборки (17), число и численности классов. Качество распознавания оказалось равно 94% (=16/17), т. е. одна из точек была классифицирована неправильно. Далее выводятся коэффициенты построенных линейных классифицирующих функций. Каждая строка (функция) соответствует своему классу. Когда нужно классифицировать новый объект, то на нем считаются значения этих трех функций и какая оказывается больше - к тому классу и относится точка. Более того, вероятностная модель позволяет каким-то способом оценить вероятность правильности этого решения.
Применим это к нашей новой точке. Для этого снова запускаем AtteStat -> Распознавание образов. Теперь переходим ко второй вкладке " Распознавание (Фишер)". В качестве объекта распознавания нужно указать диапазон C20: D20, содержащий введенную нами вручную точку. В качестве простых классифицирующих функций указываем диапазон коэффициентов, полученных нами на предыдущем шаге A48: C50. Программа выдает, что объект принадлежит классу 1 с вероятностью 0. 75.
Причина этого не очень уверенного ответа может заключаться в том, что облако второго класса достаточно сильно размыто, поэтому программа считает, что данная точка может быть сгенерирована и таким распределением.
(Дополнение: в старой версии AtteStat была ошибка, поэтому вероятность принадлежности считалась неправильно. Начиная с версии 7. 7 ошибка исправлена).
Далее можно упомянуть про кластерный анализ (хотя из задания мы его убираем). То, что мы только что рассматривали (дискриминантный анализ) еще называют " обучением с учителем", так как нам известен правильный ответ для каждого из имеющихся наблюдений. Но бывают и другие ситуации, когда мы имеем наблюдения, но не имеем никаких заранее заданных групп. Но в ряде ситуаций мы хотим выделить эти группы сами. Это задача кластерного анализа, когда программа должна сама разбить наблюдения на группы (кластеры) и выработать правило, по котрому можно будет относить к этим кластерам новые наблюдения. Мы считаем, что наблюдения близкие друг к другу (попадающие в один кластер) могут оказаться близкими друг к другу по тем или иным свойствам.
В последнем самостоятельном задании сделать следующее:
1: построить три попарные диаграммы рассеяния и выбрать ту пару переменных, при которой рассматриваемые три группы разделяются лучшим образом.
2: для данной пары переменных провести обучение процедуры дискриминантного анализа.
3: классифицировать указанную новую точку.
Обратить внимание на то, что для новой точки даны значения всех трех переменных, но для классификации нужно, разумеется, использовать те же две, по которым происходило обучение. Также заметить, что если наилучшие переменные оказались AC, то придется для обучения скопировать их в отдельные столбцы, чтобы их можно было указать в виде отдельного диапазона.
Обратите внимание, что выводимую вероятность нельзя скопировать, и придется ее переписать вручную.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|