- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Двоичный код — это способ представления данных в одном разряде в виде комбинации двух знаков, обычно обозначаемых цифрами 0 и 1. Разряд в этом случае называется двоичным разрядом.
11. Циклические коды. Выбор образующего полинома.
Циклический код — линейный код (тип блокового кода, использующийся в схемах определения и коррекции ошибок), обладающий свойством цикличности, то есть каждая циклическая перестановка кодового слова также является кодовым словом. Используется для преобразования информации для защиты её от ошибок.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию, а при чтении (приеме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного кода.
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и сверточные, работающие с данными как с непрерывным потоком.
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному 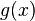 . Порождающий полином является делителем
. Порождающий полином является делителем 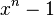 .
.
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
- несистематическое кодирование осуществляется путем умножения кодируемого вектора на :
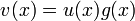 ;
;
- систематическое кодирование осуществляется путем «дописывания» к кодируемому слову остатка от деления
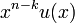 на , то есть
на , то есть 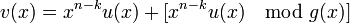 .
.
12. Базис циклического кода, формирование кодовых комбинаций.
Циклические коды – это блочные линейные коды. Строятся с помощью образующего полинома 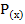 - поэтому называются полиномиальными.
- поэтому называются полиномиальными.
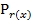 - образующий полином степени r, выбирается из таблицы – группы неприводимых многочленов.
- образующий полином степени r, выбирается из таблицы – группы неприводимых многочленов.
Если необходим код с исправлением ошибок, то из таблицы неприводимых многочленов выбирается примитивный.
Все разрешающие комбинации делятся на и дают (n+1) разных остатков.
Над кодовыми комбинациями выполняются математические действия – умножение, деление, сумма по модулю два.
13. Синдром циклического кода и его свойства.
Циклический код:
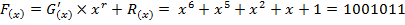
Декодирование выполняется делением полученной комбинации 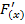 на образующий полином
на образующий полином 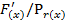 =
= 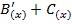 . По виду синдрома
. По виду синдрома 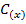 можно сделать вывод о наличии ошибок.
можно сделать вывод о наличии ошибок.

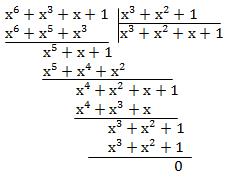
Синдром - это код, количество разрядов в котором совпадает с количеством проверочных символов. Если синдром нулевой (с=000), то поступивший с выхода канала код верен. Если ходя бы один разряд синдрома не равен нулю, то в принятом коде есть ошибка, причем вид синдрома (количество и порядок единиц в нем) указывает на разряд, в котором ошибка произошла.
Если в синдроме одна «1», то ошибка произошла в проверочном разряде, если две и более, то в информационном.
14. Свёрточные коды: парметры, диаграмма состояний, решетчатая диаграмма.
Свёрточный код — это корректирующий ошибки код, в котором
(a) на каждом такте работы кодера 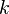 символов входной полубесконечной последовательности преобразуются в
символов входной полубесконечной последовательности преобразуются в 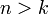 символов выходной, и
символов выходной, и
(b) в преобразовании также участвуют 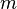 предыдущих символов;
предыдущих символов;
(c) выполняется свойство линейности (если двум кодируемым последовательностям 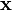 и
и 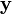 соответствуют кодовые последовательности
соответствуют кодовые последовательности 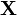 и
и 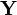 , то кодируемой последовательности
, то кодируемой последовательности  соответствует
соответствует 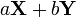 ).
).
Сверточные коды по классификации относятся к непрерывным кодам, их можно применять для блочной структуры. Коды строятся на основе генераторных полиномов. В отличии от блочных кодов это коды с памятью, то есть при кодировании очередного бита участвуют два предыдущих бит – это память кода.
Структуру кода определяют нижеследующие характеристики:
1. Число информационных символов, поступающих за один такт на вход кодера — k.
2. Число символов на выходе кодера — n, соответствующих k, поступившим на вход символам в течение такта.
3. Скорость кода определяется отношением R=k/n и характеризует избыточность, вводимую при кодировании.
4. Избыточность кода 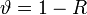
5. Память кода (входная длина кодового ограничения или информационная длина кодового слова), определяется максимально степенью порождающего многочлена в составе порождающей матрицы G(X):
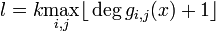
6. Маркировка сверточного кода обозначается в большинстве случаев (n, k, l), но возможны и вариации.
7. Вес w двоичных кодовых последовательностей определяется числом «единиц», входящих в эту последовательность или кодовые слова.
8. Кодовое расстояние 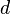 показывает степень различия между i-й и j-й кодовыми комбинациями при условии их одинаковой длины. Для любых двух двоичных кодовых комбинаций кодовое расстояние равно числу несовпадающих в них символов. В общем виде кодовое расстояние может быть определено как суммарный результат сложения по модулю 2 одноименных разрядов кодовых комбинаций
показывает степень различия между i-й и j-й кодовыми комбинациями при условии их одинаковой длины. Для любых двух двоичных кодовых комбинаций кодовое расстояние равно числу несовпадающих в них символов. В общем виде кодовое расстояние может быть определено как суммарный результат сложения по модулю 2 одноименных разрядов кодовых комбинаций 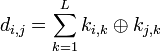 , где
, где 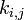 и
и 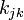 — k-е символы кодовых комбинаций i и j; L- длина кодовой комбинации.
— k-е символы кодовых комбинаций i и j; L- длина кодовой комбинации.
9. Минимальное кодовое расстояние 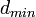 — это наименьшее расстояние Хемминга для набора кодовых комбинаций постоянной длины. Для его нахождения необходимо перебрать все возможные пары кодовых комбинаций. Тогда получаем
— это наименьшее расстояние Хемминга для набора кодовых комбинаций постоянной длины. Для его нахождения необходимо перебрать все возможные пары кодовых комбинаций. Тогда получаем 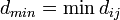 . Но! Это определение справедливо для блочных кодов имеющих постоянную длину. Сверточные коды являются непрерывными и характерризуются многими минимальными расстояниями, определяемыми длинами начальных сегментов кодовых последовательностей, между которыми берется минимальное расстояние. Число символов в принятой для обработки длине сегменты L определяет на приемной стороне число ячеек в декодирующем устройстве.
. Но! Это определение справедливо для блочных кодов имеющих постоянную длину. Сверточные коды являются непрерывными и характерризуются многими минимальными расстояниями, определяемыми длинами начальных сегментов кодовых последовательностей, между которыми берется минимальное расстояние. Число символов в принятой для обработки длине сегменты L определяет на приемной стороне число ячеек в декодирующем устройстве.
Работу кодера можно показать в виде граф состояний.
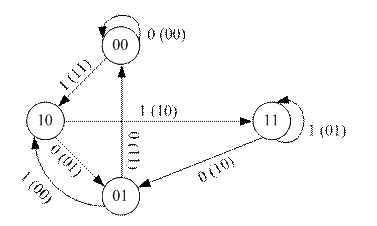
Основной параметр кодовое расстояние – это минимальное расстояние Хэмминга между всеми комбинациями.
Из всех возможных путей по диаграмме состояния (решетке) наиболее правильным путем кодирования выбирается тот, который имеет минимальное расстояние Хэмминга.
 При условии, что путь пройдет по диаграмме.
При условии, что путь пройдет по диаграмме.
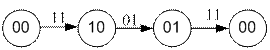
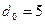 (Определяется количеством единиц).
(Определяется количеством единиц).
Из всех вариантов декодирования, разработанных в теории, наибольшее применение нашел алгоритм Витерби. В его основе представлена процедура кодирования и декодирования с помощью решетки. Решетка это одно из представлений кодового дерева.
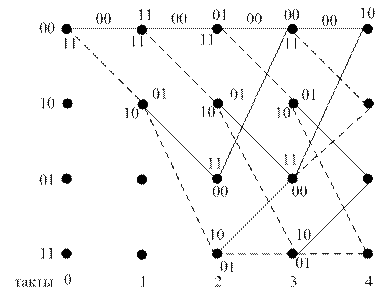
15. Декодирование сверточных кодов по алгоритму Витерби.
Из всех вариантов декодирования, разработанных в теории, наибольшее применение нашел алгоритм Витерби. В его основе представлена процедура кодирования и декодирования с помощью решетки. Решетка это одно из представлений кодового дерева.
 Пример: кодер пришел в состояние 00 … 1011.
Пример: кодер пришел в состояние 00 … 1011.
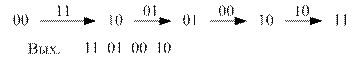
Анализируя на каждом шаге входные биты декодирования, рассматриваются все возможные пути (переходы) по решетке и для каждого пути считается расстояние Хэмминга между входными битами и состояниями ребер данного блока.
Подсчитываются метрики (расстояние) ребер и путей. Пути с большим расстоянием отбрасываются в процессе анализа – такие блоки называются умершими. А пути с меньшими метриками продолжают анализироваться. Правильный считается путь с наименьшей метрикой.

В итоге остается только один путь.
Если ошибок не было, то минимальная метрика равна нулю. При наличии ошибок не будет путей с метрикой ноль, 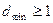 .
.
16. Каскадные коды. Турбо-коды.
Турбо-код — параллельный каскадный блоковый систематический код, способный исправлять ошибки, возникающие при передаче цифровой информации по каналу связи с шумами. Синонимом турбо-кода является известный в теории кодирования термин — каскадный код. Важным преимуществом турбо-кодов является независимость сложности декодирования от длины информационного блока, что позволяет снизить вероятность ошибки декодирования путём увеличения его длины. Основной недостаток турбо-кодов — это относительно высокая сложность декодирования и большая задержка, которые делают их неудобными для некоторых применений.
Особенностью турбо-кодов является параллельная структура, состоящая из рекурсивных систематических сверточных (RSC) кодов, работающих параллельно и использующих создание случайной версии сообщения. Параллельная структура использует два или больше кодов RSC, каждый с различным перемежителем. Цель перемежителя состоит в том, чтобы предложить каждому кодеру некоррелированную или случайную версию информации, в результате чего паритетные биты каждого RSC становятся независимыми.
В турбо-кодах блоки имеют длину порядка нескольких Кбит. Цель такой длины состоит в том, чтобы эффективно рандомизировать последовательность, идущую на второе кодирующее устройство. Чем длиннее размер блока, тем лучше его корреляция с сообщением первого кодера, то есть корреляция мала.
17. Кодирование в линиях связи. Двоичные линейные коды. Многоуровневые коды.
Двоичный код — это способ представления данных в одном разряде в виде комбинации двух знаков, обычно обозначаемых цифрами 0 и 1. Разряд в этом случае называется двоичным разрядом.
Линейным двоичным кодом длины n называется множество двоичных последовательностей длины n, для которого выполняются 2 условия:
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|