- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
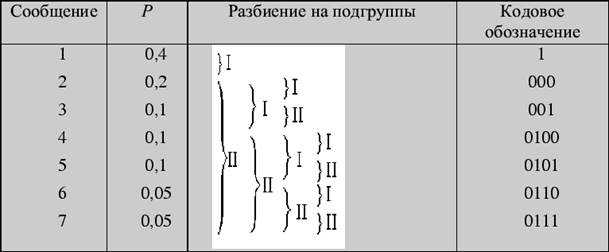
Решение 2 (табличный способ). Решение 1. Первый шаг
Решение 2 (табличный способ)
Цена кодирования (средняя длина кодового слова 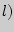 является критерием степени оптимальности кодирования. Вычислим ее в нашем случае.
является критерием степени оптимальности кодирования. Вычислим ее в нашем случае.
Для того чтобы закодировать сообщения по Хаффману, предварительно преобразуется таблица, задающая вероятности сообщений. Исходные данные записываются в столбец, две последние (наименьшие) вероятности в котором складываются, а полученная сумма становится новым элементом таблицы, занимающим соответствующее место в списке убывающих по величине вероятностей. Эта процедура продолжается до тех пор, пока в столбце не останутся всего два элемента.
Пример 2. Закодировать сообщения из предыдущего примера по методу Хаффмана.
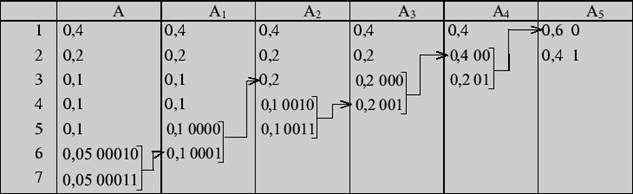
Решение 1. Первый шаг

Вторым шагом производим кодирование, "проходя" по таблице справа налево (обычно это проделывается в одной таблице):
Решение 2. Построение кодового дерева начинается с корня. Двум исходящим из него ребрам приписывается в качестве весов вероятности 0,6 и 0,4, стоящие в последнем столбце. Образовавшимся при этом вершинам дерева приписываются кодовые символы 0 и 1. Далее "идем" по таблице справа налево. Поскольку вероятность 0,6 является результатом сложения двух вероятностей 0,4 и 0,2, из вершины 0 исходят два ребра с весами 0,4 и 0,2 соответственно, что приводит к образованию двух новых вершин с кодовыми символами 00 и 01. Процедура продолжается до тех пор, пока в таблице остаются вероятности, получившиеся в результате суммирования. Построение кодового дерева заканчивается образованием семи листьев, соответствующих данным сообщениям с присвоенными им кодами. Дерево, полученное в результате кодирования по Хаффману, имеет следующий вид:
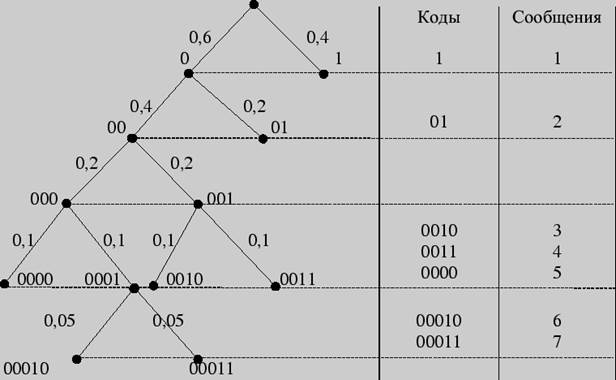
Рис. 2
Листья кодового дерева представляют собой кодируемые сообщения с присвоенными им кодовыми словами. Таблица кодов имеет вид:
| сообщение | |||||||
| код |
Цена кодирования здесь будет равна
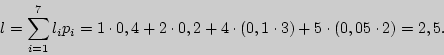
Для передачи данных сообщений можно перейти от побуквенного (поцифрового) кодирования к кодированию "блоков", состоящих из фиксированного числа последовательных "букв".
Пример 3. Провести кодирование по методу Фано двухбуквенных комбинаций, когда алфавит состоит из двух букв 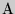 и
и 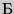 , имеющих вероятности
, имеющих вероятности  = 0,8 и
= 0,8 и  = 0,2.
= 0,2.
Решение.
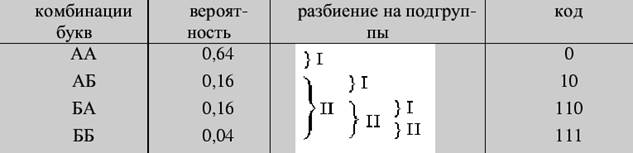
Цена кода 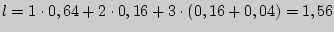 , и на одну букву алфавита приходится 0,78 бита информации. При побуквенном кодировании на каждую букву приходится следующее количество информации:
, и на одну букву алфавита приходится 0,78 бита информации. При побуквенном кодировании на каждую букву приходится следующее количество информации:
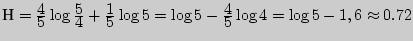 (бит).
(бит).
Пример 4. Провести кодирование по Хаффману трехбуквенных комбинаций для алфавита из предыдущего примера.

Построим кодовое дерево.
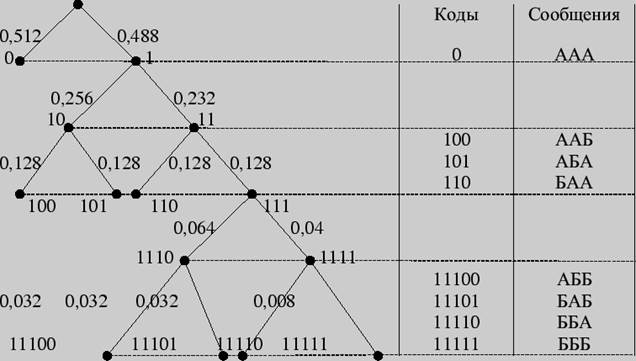
Рис. 3
Найдем цену кодирования
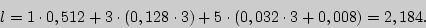
На каждую букву алфавита приходится в среднем 0,728 бита, в то время как при побуквенном кодировании - 0,72 бита.
Большей оптимизации кодирования можно достичь еще и использованием трех символов - 0, 1, 2 - вместо двух. Тринарное дерево Хаффмана получается, если суммируются не две наименьшие вероятности, а три, и приписываются каждому левому ребру 0, правому - 2, а серединному - 1.
Пример 5. Построить тринарное дерево Хаффмана для кодирования трехбуквенных комбинаций из примера 4.
Решение. Составим таблицу тройного "сжатия" по методу Хаффмана

Тогда тринарное дерево выглядит следующим образом:
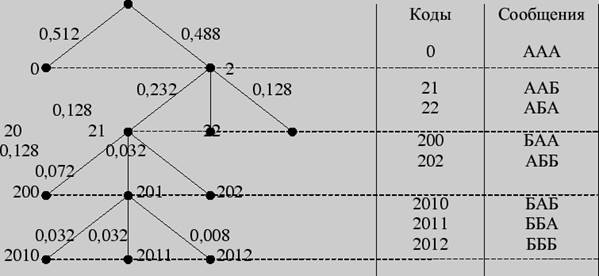
Рис. 4
Задачи
I1. Проведите кодирование по методу Фано алфавита из четырех букв, вероятности которых равны 0,4; 0,3; 0,2 и 0,1.
2. Алфавит содержит 7 букв, которые встречаются с вероятностями 0,4; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05. Осуществите кодирование по методу Фано.
3. Алфавит состоит из двух букв, 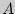 и , встречающихся с вероятностями
и , встречающихся с вероятностями 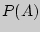 = 0,8 и
= 0,8 и 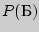 = 0,2. Примените метод Фано к кодированию всевозмож-ных двухбуквенных и трехбуквенных комбинаций.
= 0,2. Примените метод Фано к кодированию всевозмож-ных двухбуквенных и трехбуквенных комбинаций.
4. Проведите кодирование по методу Хаффмана трехбуквенных слов из предыдущей задачи.
5. Проведите кодирование 7 букв из задачи 302 по методу Хаффмана.
6. Проведите кодирование по методам Фано и Хаффмана пяти букв, равновероятно встречающихся.
II 7. Осуществите кодирование двухбуквенных комбинаций четырех букв из задачи 301.
8. Проведите кодирование всевозможных четырехбуквенных слов из задачи 303.
III 9. Сравните эффективность кодов Фано и Хаффмана при кодировании алфавита из десяти букв, которые встречаются с вероятностями 0,3; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05; 0,04; 0,03; 0,03.
10. Сравните эффективность двоичного кода Фано и кода Хаффмана при кодировании алфавита из 16 букв, которые встречаются с вероятностями 0,25; 0,2; 0,1; 0,1; 0,05; 0,04; 0,04; 0,04; 0,03; 0,03; 0,03; 0,03; 0,02; 0,02; 0,01; 0,01.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|