- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Рис. 8. Шаг работы декодировщика LZW в случае 1
Лекция 3. LZW метод. Алгоритм декодирования
Кладем в словарь символы a, b, c, … под номерами 0 .. 255, соответственно.
пока (поток не пуст)
код = следующий код из потока
1 если (в словаре есть слово для кода) (рис. 8)
вывести содержимое_словаря(по коду)
добавить в словарь(содерж_словаря(по прошлому_коду) +перв_символ(содерж_словаря(по коду)) )
2 иначе
строка = содерж_словаря(по прошлому_коду) + перв_символ(содерж_словаря(по прошлому_коду))
вывести(строка)
добавить в словарь(строка)
конец если
конец пока
конец алгоритма
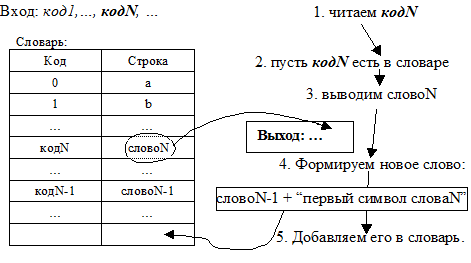
Рис. 8. Шаг работы декодировщика LZW в случае 1
Возникают следующие вопросы.
1. Пока в словарь добавили мало слов, на представление кода можно отводить меньше бит: до 512 слов — 9 бит на код, от 512 до 1024 — 10 бит и т.д. Изменение длины кодов должны контролировать и кодировщик, и декодировщик.
2. Если словарь кончится: обнуляем словарь (главное, это должны знать и кодировщик, и декодировщик).
3. Чтобы поиск последовательности в словаре занимал меньше времени можно организовать словарь в виде бинарного дерева поиска.
При сравнительно небольших затратах на одну кодовую комбинацию получается достаточно большой диапазон номеров, например, при 12 битах (полтора байта) можно закодировать примерно 4000 строк и не требуется никаких дополнительных затрат на таблицу исходных символов.
Важное преимущество LZ-методов и в том, что они адаптивны, т. е. сами приспосабливаются к особенностям текста и не требуют предварительного просмотра, как метод Хаффмена.
Сейчас массовое использование персональных компьютеров сделало популярными многочисленные "архивирующие программы", среди них наиболее известны arj, zip, zoo, rar, а в среде UNIX — программы compress, gzip, compact. Популярна сжатая система хранения информации на диске. В системе программирования JAVA предусмотрено хранение в сжатой форме исполняемых файлов. Алгоритмическую основу архивирующих программ образуют методы Хаффмена и Зива—Лемпеля с различными модификациями и усовершенствованиями.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|