- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Раздел 1. Основные алгоритмы сжатия текстовой информации. 1. Общие положения
Раздел 1. Основные алгоритмы сжатия текстовой информации. 1. Общие положения
Все алгоритмы, реализующие сжатие текстовой информации, относятся к классу «сжимающих без потерь» (lossless data compression). Это означает, что если у нас есть некоторый текст Xn, хранящийся в электронном виде в стандартной двоичной кодировке Unicode и имеющий объем n байт, и некоторый алгоритм компрессии 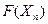 , преобразующий этот текст в поток символов Ym объема m < n, то существует обратной алгоритм
, преобразующий этот текст в поток символов Ym объема m < n, то существует обратной алгоритм 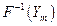 , который называется алгоритмом декомпрессии, такой что
, который называется алгоритмом декомпрессии, такой что 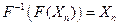 .
.
К. Шеннон и Р. Фано предложили в наиболее чистом виде конструкцию кода переменной длины. В этом коде у каждого символа своя длина кодовой последовательности, как в азбуке Морзе. Но в отличие от азбуки Морзе, где конец кодовой последовательности определяется "третьим символом" — паузой, здесь нужно побеспокоиться о том, как определять завершение кода отдельного символа. Предлагается такое ограничение на код: никакая кодовая последовательность не является началом другой кодовой последовательности. Это свойство называется свойством префикса, а код, обладающий таким свойством, называется префиксным кодом.
В предположении, что кодируемые символы появляются в тексте независимо нужно стремиться уменьшать среднее число битов на один символ, т.е. математическое ожидание длины кодовой комбинации случайно выбранного символа, которое равно
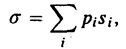
где pi — вероятность, а si — длина кодовой последовательности i-го символа.
Получается экстремальная задача.
Задача о префиксном коде. Минимизировать математическое ожидание 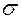 по всем наборам длин { si }, удовлетворяющим неравенству Крафта.
по всем наборам длин { si }, удовлетворяющим неравенству Крафта.
Теорема Крафта: Для того, чтобы набор целых чисел 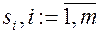 , мог быть набором длин путей поиска в схеме с
, мог быть набором длин путей поиска в схеме с  исходами, необходимо и достаточно, чтобы
исходами, необходимо и достаточно, чтобы
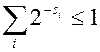 .
.
Набор, для которого минимально, называется оптимальным. Шеннон и Фано предложили строить код, близкий к оптимальному, следующим способом: разбить все символы на две группы с приблизительно равными суммарными вероятностями, коды первой группы начать с 0, а второй группы — с 1; внутри каждой группы делать то же самое, пока в каждой группе не останется только по одному символу.
Элегантный алгоритм для точного решения этой задачи предложил Д. Хаффмен. Алгоритм основывается на нескольких очевидных свойствах оптимального набора {sj}.
Лемма 1. Пусть {рi} — набор вероятностей символов и {si} — длины оптимальных кодовых комбинаций. Если p1 > р2 >•••> рп, то s1 < s2 < ••• <sn.
Доказательство. Здесь достаточно сослаться на уже встречавшуюся нам задачу о перестановке, минимизирующей скалярное произведение двух векторов.
Задача о минимуме скалярного произведения Пусть заданы т чисел х1 х2,.. , хm и еще т чисел у1, у2,..., ym. Составим пары (х, у), включив каждое хi, и каждое уj ровно в одну пару Затем перемножим числа каждой пары и сложим получившиеся произведения. Требуется найти такое разбиение чисел на пары, при котором значение получившейся суммы будет наименьшим.
Теорема. Наименьшее значение суммы попарных произведений достигается при сопоставлении возрастающей последовательности x, убывающей последовательности у.
Доказательство Покажем, что если найдутся две пары чисел 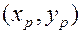 и
и  , такие что
, такие что 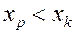 и
и 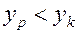 , то значение суммы попарных произведений можно уменьшить, заменив эти две пары парами
, то значение суммы попарных произведений можно уменьшить, заменив эти две пары парами  и
и  Действительно, так как
Действительно, так как
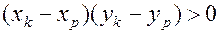 , то
, то
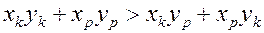 .
.
Поскольку число возможных расположении равно т!, т.е. конечное число, то начиная с любого расположения за конечное число шагов мы закончим процесс улучшений на расположении, которое дальше улучшить невозможно. На нем и достигается минимум.
Лемма 2. В обозначениях и предположении леммы 1 две самые длинные кодовые комбинации имеют одинаковую длину, т.е.  .
.
Лемма 3. Рассмотрим наравне с исходной задачей Р сокращенную задачу Р', которая получается объединением двух самых редких символов в один символ, — в предположении леммы 1 это два последних символа с суммарной вероятностью 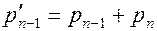 . Минимальное значение целевой функции в задаче Р' отличается от значения в задаче Р на
. Минимальное значение целевой функции в задаче Р' отличается от значения в задаче Р на 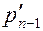 , а оптимальный кодовый набор для задачи Р получается из решения для задачи Р' удлинением на один бит кодовой последовательности для объединенного символа.
, а оптимальный кодовый набор для задачи Р получается из решения для задачи Р' удлинением на один бит кодовой последовательности для объединенного символа.
Алгоритм, основанный на этих леммах, описывается в несколько строк: если в алфавите два символа, то нужно закодировать их 0 и 1, а если больше, то соединить два самых редких символа в один новый символ, решить получившуюся задачу и вновь разделить этот новый символ, приписав 0 и 1 к его кодовой последовательности.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|