- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Семинар 11. Тема – Технология OpenМР: параллельное выполнение циклов
Семинар 11
Тема – Технология OpenМР: параллельное выполнение циклов
В OpenMP, наряду с поддержкой организации явного параллелизма с использованием нумерации нитей в параллельных блоках, существуют также возможности для автоматического распараллеливания на основе указаний компилятору с помощью соответствующих директив.
Директива for является указанием компилятору, что итерации данного цикла можно выполнить параллельно. Распределение итераций цикла между нитями возлагается на компилятор и зависит от количества нитей, выполняющих данный фрагмент кода, а также от количества итераций в цикле. В частности, применение директивы for в области, выполняемой одной нитью, не является ошибкой, однако в этом случае цикл будет выполнен в последовательном режиме нитью-мастером.
После директивы for обязательным условием является наличие в следующей строке соответствующего оператора цикла.
Варианты применения прагмы omp for:
1. Если параллельный регион создается только для распараллеливания цикла, можно совместить директивы parallel и for в одной строке:
#pragma omp parallel for
for(i=0; i<N;i++) { // начало параллельного блока и одновременно открытие цикла
…
} // закрытие цикла и параллельного блока
2. Если в параллельной области, помимо цикла, присутствуют какие-либо еще вычисления, директива for применяется внутри параллельной области непосредственно перед оператором цикла:
#pragma omp parallel
{ // начало параллельного блока
…
#pragma omp for
for (i=0; i<N;i++) { // открытие цикла
…
} // закрытие цикла
…
} // закрытие параллельного блока
Пример 1
Рассмотрим применение прагмы omp for для поэлементного сложения двух массивов.
В программе задаются значения элементов целочисленных массивов a и b длины N.
Далее организуется параллельная область, в которой прагма omp for применяется для выполнения цикла. В цикле организуется на каждой итерации печать индекса i и номера нити, выполняющего эту итерацию. Соответственно, можно проследить – как компилятор распределил итерации между нитями.
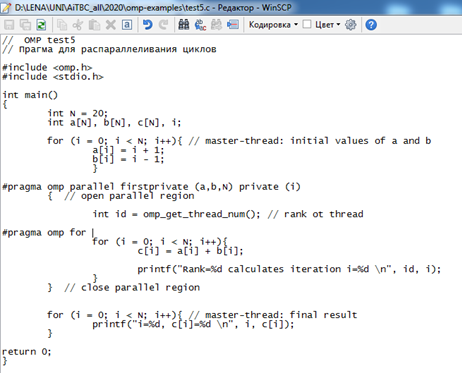
Обращаем внимание, что в приведенном примере программы a,b,N определены в параллельной области как firstprivate, чтобы передать значения этих данных внутрь параллельной области. Можно было бы сделать эти переменные общими, но работа с локальными данными более «рентабельна» с точки зрения затрат компьютерного времени. Объявление private(i) дает возможность корректно использовать индекс i как в мастер-нити, так и в параллельной области. Массив с имеет тип shared по умолчанию.
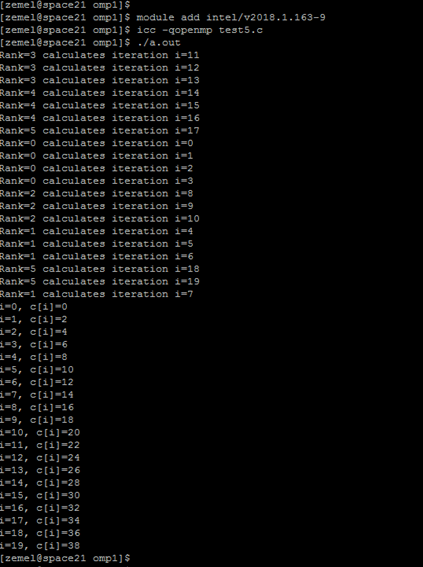
На скриншоте с результатами работы программы видим, что программа сработала с числом нитей 6 (значение по умолчанию для интерактивного запуска).
Нить с номером 0 выполнила итерации цикла для i=0,1,2,3, нить с номером 1 посчитала элементы массива с[N] с номерами 4,5,6,7 и т.д.
Таким образом, каждой нити достался в работу блок данных из 3 или 4 элементов.
Если запустить программу с другим количеством нитей – распределение итераций между нитями изменится, но конечный результат (значения массива с) не изменится.
Некоторые полезные опции директивы for:
lastprivate – если переменная объявлена lastprivate, внутри параллельной области она ведет себя как private, а после завершения цикла имеет значение, полученное на последней итерации.
nowait – по завершении выполнения цикла позволяет нитям не ждать друг друга, а продолжать работу каждой нити сразу после выполнения назначенных ей итераций.
collapse – позволяет ассоциировать с директивой for блок тесновложенных циклов, итерации которых в совокупности распределяются между нитями.
schedule – регулирование распределения итераций цикла между нитями. Параметрами этой опции являются тип распределения (static, dynamic, guided, auto и др.) и количество итераций, назначаемых к выполнению каждой нити. Разберем подробнее работу этой опции.
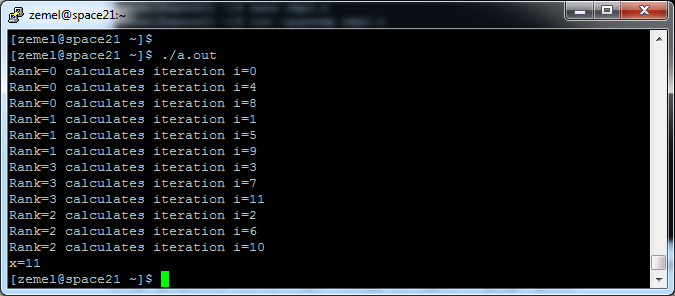
Пример 2. Рассматриваем цикл из 12 итераций, указываем число нитей 4 и распределение итераций типа static.

Также в этом примере демонстрируется применение опции lastprivate относительно переменной х, куда сохраняется значение индекса i.

Видно, что каждая нить выполняет блок из трех итераций. При этом значение х=11 в конце программы соответствует номеру последней итерации цикла.
По умолчанию реализуется именно такое – статическое – распределение итераций между нитями (static), аналогичное «блочному» распределению итераций цикла, рассмотренному нами на семинарах по MPI.
Укажем теперь для распределения static порцию итераций, назначаемых каждой нити, равную 1:
#pragma omp for lastprivate(x) schedule (static,1)
Получили распределение итераций цикла между нитями, аналогичное рассмотренному нами ранее для MPI «циклическому» распараллеливанию:
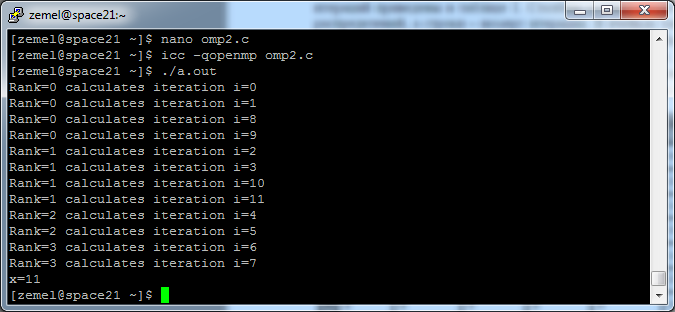
Если указать
#pragma omp for lastprivate(x) schedule (static,2)
Каждая нить выполняет по две итерации по возрастанию их номеров, затем еще по две и т.д. Таким образом, 0-нить выполняет итерации с номерами 0,1, затем 8,9; 1-нить выполняет итерации 2,3, затем10,11; нитям с номерами 2 и 3 достаются соответственно итерации 4,5 и 6,7.
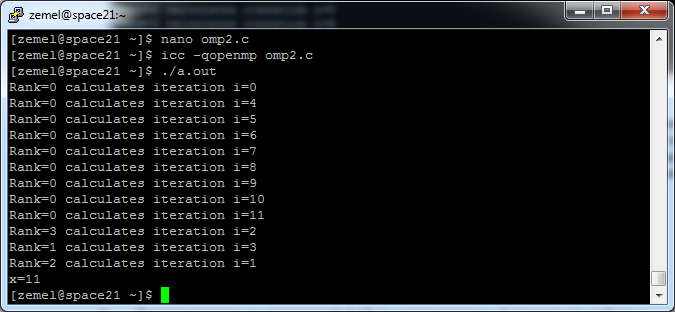
При использовании опций dynamic или guided каждая нить получает заданную порцию итераций и по мере их выполнения берет себе в работу следующие итерации по определенной схеме. При таком режиме количество итераций между нитями распределяется неравномерно, может оказаться, что большинство итераций успела выполнить одна нить (особенно, если число итераций невелико). При этом распределение итераций между нитями может меняться от запуска к запуску. Так, на скриншоте с результатом запуска при использовании опции dynamic
#pragma omp for lastprivate(x) schedule (dynamic)
видно, что 9 из 12 итераций цикла выполнены нитью с номером 0:
Задание
1. Воспроизвести на кластере Hybrilit вышеприведенные примеры по работе c прагмой omp for. Выполнить запуск программы из примера 1 с количеством нитей 4 и 5. Определить – сколько элементов массива с вычисляет каждая нить.
2. Составить и запустить OpenMP-программу, выполняющую следующее. Задается массив Х из 15 целых чисел, каждое из которых равно 10. Организуется параллельная область, в которой c помощью прагмы for реализуется параллельное выполнение цикла. Внутри цикла к каждому элементу массива X прибавляется число, равное количеству параллельных нитей и выводится на печать номер этого элемента и номер нити. После завершения параллельного блока выводятся на экран результирующие значения массива X.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|