- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Семинар 5.. Тема: Технология MPI: Коллективное взаимодействие процессов. Введение
Семинар 5.
Тема: Технология MPI: Коллективное взаимодействие процессов
План:
· Введение
· Функции коллективного взаимодействия процессов MPI_Bcast и MPI_Reduce. Пояснения и примеры.
· Задания
Введение
На предыдущих семинарах уже освоили применение функций технологии MPI:
Функции общего назначения (4 штуки)
MPI_Init – инициализация работы с MPI
MPI_Finalize – завершение работы с MPI
MPI_Comm_rank – определение номера процесса
MPI_Comm_size – определение размера группы (количества процессов в группе)
Функции для организации обмена между отдельными процессами
MPI_Send – блокирующая отправка данных процессу с заданным номером
MPI_Recv – блокирующий прием данных от процесса с заданным номером
MPI_Isend – неблокирующая отправка данных процессу с заданным номером
MPI_Irecv – неблокирующий прием данных от процесса с заданным номером
MPI_Test – вспомогательная функция для проверки завершения неблокироющего приема или передачи
MPI_Wait – вспомогательная функция, обеспечивающая ожидание завершения приема или передачи
Еще одно важное семейство операций – операции коллективного обмена.
Отличительные особенности коллективных операций:
· в таких операциях участвуют ВСЕ процессы группы
· процедуры коллективного взаимодействия должны быть согласованно вызваны ВСЕМИ процессами группы
· коллективные коммуникации НЕ взаимодействуют с процедурами типа «точка – точка»
· возврат из процедуры коллективного обмена в каждом процессе происходит тогда, когда его участие в коллективной операции завершилось, однако это не означает, что другие процессы также завершили операцию
· количество получаемых данных должно быть равно количеству посланных данных
· типы элементов посылаемых и получаемых сообщений должны совпадать;
· сообщения не имеют идентификаторов.
Функция MPI_Bcast для широковещательной рассылки данных
Рассылка информации от одного процесса всем остальным членам группы производится с помощью функции MPI_Bcast. Применение этой процедуры позволяет существенно сократить как объем кода, так и время выполнения рассылки по сравнению с использованием для этой цели процедур типа «точка – точка».
Функция вызывается всеми процессами в группе и имеет следующие параметры:
int MPI_Bcast(void* buf, int count, MPI_Datatype datatype, int root, MPI_Comm comm)buf — в рассылающем процессе: адрес начала расположения отправляемых данных; в остальных процессах: адрес начала буфера, где размещаются полученные данные;
count — количество отправляемых\получаемых данных;
datatype — тип отправляемых\получаемых данных;
root — номер процесса отправителя;
comm — коммуникатор, связанный с группой процессов, в рамках которой происходит операция.
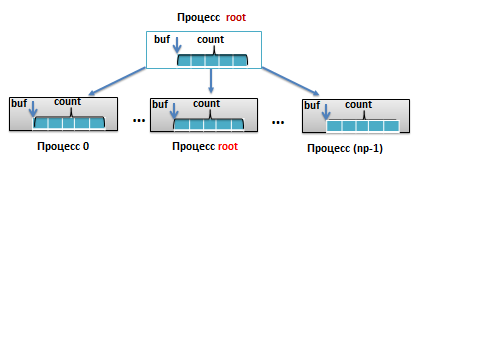
Графическая интерпретация функции MPI_Bcast: Схема рассылки данных от процесса root всем процессам в группе. Здесь np – количество процессов в группе, count – количество передаваемых элементов.
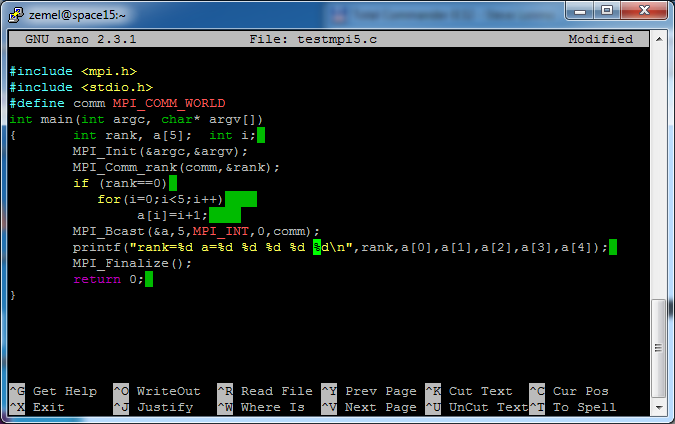
Фрагмент программы иллюстрирует рассылку значения переменной a типа double из процесса 0 всем процессам в группе, соответствующей коммуникатору MPI_COMM_WORLD.
….
int rank;
double a;
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
if(rank==0) a = 0.001;
MPI_Bcast(&a,1,MPI_DOUBLE,0, MPI_COMM_WORLD);
….
Пример 1. Широковещательная рассылка массива
Процесс с номером 0 рассылает массив а длины 5, заполненный целыми числами от 1 до 5, всем процессам в группе. После завершения пересылки каждый процесс печатает свой массив а.
Результат запуска этой программы для четырех процессов:

Видно, что все процессы корректно получили значения массива а, вычисленные в процессе с номером 0.
Функция MPI_Reduce для глобальных вычислительных операций
В параллельном программировании на базе MPI допускаются математические операции над блоками данных, распределенных между MPI-процессами. Такие операции называют глобальными операциями редукции. Подобные возможности в том или и ном виде существуют и в других технологиях параллельного программирования.
Пусть параллельная программа на определенном этапе хранит в каждом процессе частичную сумму какой-либо величины. Формирование окончательного результата в принципе возможно путем сборки всех частичных сумм в один процесс и последующего суммирования полученных данных.
Однако применение для этой цели операции глобальной редукции MPI_SUM позволит получить окончательное значение данной величины без организации пересылки этих частичных сумм в один процесс, что существенно упрощает написание программы. Использование подобных операций является одним из важных инструментов организации распределенных вычислений.
Процедура MPI_Reduce возвращает результат глобальной операции (редукции) в один процесс с указанным номером. Функция имеет вид: int MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)Параметры:
sendbuf — адрес начала расположения буфера данных, над которыми выполняется глобальная операция op;
recvbuf — адрес начала расположения в процессе с номером root буфера данных с результатами выполнения операции op;
count — количество данных;
datatype — тип данных;
op — операция редукции, выполняемая над данными sendbuf;
root — номер процесса в который записываются результаты операции op;
comm — коммуникатор группы.
Представленный фрагмент программы иллюстрирует суммирование с помощью процедуры MPI_Reduce значений, находящихся в разных процессах переменных c типа double в переменную c1, находящуюся в процессе c номером 0.
…
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
double a = 0.01*rank;
MPI_Reduce(&a,&b,1,MPI_DOUBLE,MPI_SUM,0, MPI_COMM_WORLD);
…
Графическая интерпретация этого примера дана на рисунке. Здесь np – количество процессов в группе. Для ясности переменные а из разных процессов снабжены индексом, соответствующим номеру процесса.

Пример 2.
Пусть целочисленная переменная а в каждом процессе группы имеет значение, равное номеру процесса. Сумма всех значений а записывается в S процессе с номером 0, который печатает полученный результат.

Результат запуска этой программы для четырех процессов:

Отметим: помимо уже упомянутой операции MPI_SUM, в MPI реализован целый ряд других глобальных операций, например, MPI_MAX – поиск максимума, MPI_MIN – поиск минимума, MPI_PROD – вычисление произведения и т.д.
Отметим: при применении глобальных операций к массивам данных в 3м параметре указывается длина массива. При этом результат глобальной операции также является массивом той же длины. В 0й элемент массива-результата записывается результат глобальной операции над нулевыми элементами массивов-аргументов из разных процессов, в 1й элемент – результат операции над первыми элементами массивов-аргументов, во 2й элемент – результат операции над вторыми элементами массивов-аргументов и т.д.
В случаях, когда результат глобальной операции должны «знать» все процессы группы – следует использовать функцию MPI_Allreduce.
В отличие от MPI_Reduce, функция MPI_Allreduce возвращает результат редукции всем процессам, так что номер процесса-получателя не входит в список параметров, а буфер для записи результата должен быть объявлен во всех процессах группы.
Функция имеет вид:
int MPI_Allreduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)Параметры:
sendbuf — адрес начала расположения буфера данных, над которыми выполняется глобальная операция op;
recvbuf — адрес начала расположения в каждом процессе группы, соответствующей коммуникатору comm, буфера данных с результатами выполнения операции op;
count — количество данных;
datatype — тип данных;
op — операция редукции, выполняемая над данными sendbuf;
comm — коммуникатор группы.
Задания:
1. Изучить в учебном пособии по MPI Главы 3. Особое внимание уделить разделам 3.3.1 и 3.3.4.
2. Воспроизвести и запустить на кластере HybriLIT рассмотренные примеры применения функций MPI_Bcast и MPI_Reduce.
3. Модифицировать программу из примера 1 для широковещательной рассылки целочисленной переменной Х=100 из процесса, имеющего максимальный номер в группе.
4. Модифицировать программу из примера 2 для вычисления максимального значения всех а из разных процессов, с записью результата в процесс номер 1 и печатью этого результата.
5. Модифицировать программу из примера 2 для вычисления минимального значения всех а из разных процессов, с записью результата во все процессы в группе и спечатью полученных результатом. Использовать функцию MPI_Allreduce.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|