- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Этап 1. Конвертирование и формально-логический контроль каждого из отобранных документов
МЕТОД КластеризациИ документов на основе анализа
их смыслового содержания
В статье описывается решение проблемы автоматической кластеризации документов на основе анализа их смыслового содержания на примере материалов, размещенных в средствах массовой информации. Предлагаемое решение базируется
на методах машинной грамматики, семантико-синтаксического
и концептуального анализа текстов, а также на методах выявления понятийного состава отобранных документов и формализации смыслового содержания текстов. Разработанный алгоритм процесса кластеризации документов обеспечивает возможность его реализации в полностью автоматическом режиме без предварительного машинного обучения.
Ключевые слова: автоматическая кластеризация документов, машинная грамматика, семантико-синтаксический анализ текстов, концептуальный анализ текстов, тематический концептуальный словарь, актуальный концептуальный словарь.
1. Введение
В настоящее время в технологических процессах обработки текстовой информации реализовано значительное число методов кластеризации текстов. Обычно под кластеризацией понимается процесс разделения множества документов на подмножества (кластеры), число которых и их параметры заранее неизвестны. Рассмотрим некоторые
из наиболее распространенных методов кластеризации. К таким методам можно отнести метод LSA/LSI (latent semantic analysis/indexing), метод STC (suffix tree clustering), метод Scatter/Gather, метод K-means и др. [1-6].
Метод LSA/ LSI давно известен в различных областях науки, как метод выявления латентной структуры изучаемых явлений и объектов. В рамках этого метода определяется пространство терминов, как пространство элементарных признаков, в котором изначально располагаются документы. Предполагается, что термины должны семантически быть связаны между собой, тогда документы, содержащие семантически близкие термины, сгущаются в определенных местах пространства терминов.
Метод STC кластеризует тексты в виде суффиксного дерева. Суффиксное дерево – это дерево, содержащее все суффиксы данной строки. Они состоят из вершин, ветвей
и дополнительных указателей (suffix pointer), с помощью которых добиваются линейной скорости построения деревьев. Ветви дерева обозначаются буквами или сочетаниями букв, которые являются частями суффиксов строки. Суффикс вершины получают путем объединения всех букв, находящихся на ребрах дерева (начиная от корневой до данной). Каждой вершине дерева соответствует конкретная фраза. В тех вершинах дерева, которые имеют потомков, имеются ссылки на документы, в которых встречается фраза, соответствующая вершине. Базовые кластеры образуются из множеств документов,
на которые указывают ссылки. Далее производится комбинирование базовых кластеров
и получение окончательных наборов
Методы Single Link, Complete Link, Group Average относятся к иерархическим методам, которые делятся на агломеративные и дивизимные методы. Первые объединяют объекты в множества, а вторые наоборот разделяют единое множество объектов
на подмножества. Методы Single Link, Complete Link, Group Average относятся
к агломеративным иерархическим методам, которые получили широкое распространение.
МетодSelf-Organizing Maps (метод самоорганизующихся карт Кохонена) выполняет кластеризацию документов на основе нейросети Кохонена. В результате работы этого метода получается образ документа, представляющий собой карту распределения векторов из обучающей выборки. Эта сеть обучается без учителя на основе принципа самоорганизации.
В основе метода K-means (К-средних) лежит итеративный процесс стабилизации центроидов (центра масс) кластеров, которые первоначально выбираются случайным образом для каждого из k-кластеров. Каждый документ присваивается к тому кластеру, расстояние до центра масс которого от него меньше заданного. Далее, на каждой итерации, вычисляются центры масс кластеров и документы переприсваиваются
к другому кластеру до (стабилизации) всех документов.
Метод на основе так называемого «мешка слов» (bag-of-words) относится
к наиболее простым алгоритмам кластеризации.В рамках этого метода предварительно
по выборке документов строится словарь из всех встречающихся в нем n-грамм (контактно расположенных последовательностей слов), где n меньше или равно заранее заданному значению. Документ представляется в виде вектора, состоящего из набора признаков. Каждому набору из словаря соответствует одна n-грамма. Для каждой
n-граммы вектора документа вычисляется его вес по формуле статистической меры
TF-IDF. Далее производится попарное сопоставление векторов документов путем вычисления косинусной меры близости между их векторами.
Анализ приведенных методов кластеризации документов показывает, что значительная часть этих методов опирается на формальные признаки представления текстовой информации, которые в незначительной степени связанны со смысловым содержанием текстов и только очень незначительное число методов основываются
на анализе лингвистических закономерностях смысловой структуры текстов. К таким методам можно отнести предлагаемое решение кластеризации текстов.
2. Теоретическое обоснование метода кластеризации
Предлагаемое решение задачи кластеризации базируется на концепции фразеологического концептуального анализа текстов [7,8]. В соответствии с этой концепцией смысловое содержание текстов определяется системой текстовых понятий[1]
и их смысловых отношений.
При кластеризации нужно установить как смысловую схожесть документов, так
и их различие. Смысловая схожесть документов определяется наличием в документах значительного числа одних и тех же наименований понятий, обладающих смыслоразличительной способностью, а различие документов определяется незначительным количеством (или полным отсутствием) таких понятий. Поэтому при решении задачи кластеризации необходимо из всей системы понятий, содержащейся
в отобранных документах, выделить ту систему значимых (ключевых) понятий, которая обладает достаточной смыслоразличительной способностью, обеспечивающей возможность разделения документов на кластеры с заданной полной и точностью. Такая система понятий составляет основу концептуального словаря, с помощью которого будет выявляться понятийная смыслоразличающая структура документов и строиться
их понятийный образ.
Автоматическое создание упомянутого словаря понятий достаточно подробно изложено в работах [6,8]. Отметим только то, что в основу концептуального анализа текста положены синтаксические, семантические и статистические методы анализа текстов.
Синтаксические методы позволяют выявить в текстах документов наименования понятий, представленные отдельными словами и словосочетаниями [6]. Семантических методы дают возможность установить значимые в предметной области понятия путем
их соотнесения с элементами эталонных тематических концептуальных словарей [7]. Статистические методы позволяют определить частоту встречаемости понятий
в коллекции текстов и в конкретном документе [8].
Таким образом, общее решение задачи кластеризации документов может быть сведено к следующим этапам:
1. Определение объектов признакового пространства, под которым следует понимать множество ключевых слов и словосочетаний, определяющих смысловое сходство отобранных документов.
2. Вычисление меры смысловой значимости понятий документов.
3. Установление значений меры сходства между документами.
4. Автоматическое формирование кластеров отобранных документов.
5. Проверка истинности результатов кластерного решения.
3. Описание решения задачи кластеризации документов
Решение задачи кластеризации можно условно разделить на несколько этапов,
в рамках которых производятся технологические операции формализации представления содержанием отдельных документов, выявления смыслоразличающего понятийного состава этих документов и представления обобщенного содержания кластеров документов в виде дайджеста кратких рефератов.
На первом этапе нужно определить множество слов и словосочетаний признакового пространства, по которым будет производиться установление смысловой схожести содержания отобранных документов. Для этого необходимо установить,
по каким критериям нужно оценивать смысловую значимость каждого элемента признакового пространства и в соответствие с этими критериями назначить каждому слову или словосочетанию весовой коэффициент их смысловой значимости
в признаковом пространстве.
В качестве меры смысловой значимости слов и словосочетаний используется статистическая мера TF-IDF (TF – частота слова, IDF – инверсия частоты).
TF – частота слова рассчитывается как отношение числа вхождений наименования понятия к общему числу наименований понятий в конкретном документе. Оценка важности наименования понятия  в пределах отдельного документа вычисляется
в пределах отдельного документа вычисляется
по формуле:
 , (1)
, (1)
где  – число вхождений наименования понятия t в документ;
– число вхождений наименования понятия t в документ;
 – общее число наименований понятий в данном документе.
– общее число наименований понятий в данном документе.
IDF – инверсия частоты, с которой некоторое наименование понятия встречается
в отобранных документах. Для каждого уникального слова в пределах конкретного перечня отобранных документов существует только одно значение IDF.
 , (2)
, (2)
где  – число отобранных документов;
– число отобранных документов;
 – число отобранных документов D, в которых встречается
– число отобранных документов D, в которых встречается
t (когда  ).
).
Мера TF-IDF является произведением двух сомножителей:
 (3)
(3)
Большой вес в TF-IDF получат наименования понятий
с высокой частотой встречаемости в конкретном документе и с относительно низкой частотой в пределах всего корпуса текстов.
Но данная статистическая мера в явном виде не отражает смысловую составляющую наименований понятий. С этой целью была разработана система коррелирующих семантических весовых коэффициентов наименований понятий, восполняющих этот пробел. Обобщенная мера смысловой значимости наименований понятий 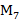 с учетом этих коэффициентов вычисляются по формуле:
с учетом этих коэффициентов вычисляются по формуле:
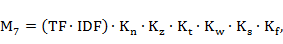 (4)
(4)
где  – коэффициент, учитывающий распознающую способность слов
– коэффициент, учитывающий распознающую способность слов
при их нормализации;
 – коэффициент, учитывающий вхождение в заголовки слов или словосочетаний;
– коэффициент, учитывающий вхождение в заголовки слов или словосочетаний;
 – коэффициент, учитывающий вхождение в тезаурус слов или словосочетаний;
– коэффициент, учитывающий вхождение в тезаурус слов или словосочетаний;
 – коэффициент, учитывающий количество слов в словосочетании;
– коэффициент, учитывающий количество слов в словосочетании;
– коэффициент, учитывающий синтаксическую роль слова или словосочетания в предложении;
 – коэффициент, учитывающий принадлежность понятия к фамильно-именной группе, бренду и др.
– коэффициент, учитывающий принадлежность понятия к фамильно-именной группе, бренду и др.
Для реализации процесса установления меры смысловой значимости наименований понятий в отобранных документах было проведено исследование по созданию актуального семантического словаря (далее – АСС) для кластеризации текстов методами приближенного концептуального анализа текстов [6].
В рамках данного исследования составлен частный частотный словарь наименований понятий и установлена взаимосвязь между покрытия текстов понятиями, содержащимися в отобранных документах, и рангами значений их частот.
Характеристики частного частотного словаря наименований понятий, сформированные в результате обработки 2 013 документов (размещенных в средствах массовой информации текстов), представлены в таблице 1.
Таблица 1.
Характеристики частного частотного словаря наименований понятий
Ранг. частот

|
Частота

|
Кратность

| Накопленная
частота
| Накопленная
кратность

| Относительная накоп. частота

|
| 55 255 | 55 255 | 0.030403 | |||
| 42 487 | 97 742 | 0.053780 | |||
| 38 668 | 136 410 | 0.075056 | |||
| 38 112 | 174 522 | 0.096026 | |||
| 20 854 | 195 376 | 0.107500 | |||
| 18 464 | 213 840 | 0.117659 | |||
| 16 508 | 230 348 | 0.126742 | |||
| 16 391 | 246 739 | 0.135761 | |||
| 15 827 | 262 566 | 0.144470 | |||
| 14 969 | 277 535 | 0.152706 | |||
| 12 311 | 413 659 | 0.227604 | |||
| 7 762 | 512 051 | 0.281742 | |||
| 6 866 | 584 223 | 0.321452 | |||
| 5 326 | 708 632 | 0.389905 | |||
| 4 183 | 756 477 | 0.416230 | |||
| 3 564 | 794 862 | 0.437350 | |||
| 3 217 | 828 605 | 0.455917 | |||
| 2 699 | 858 548 | 0.472392 | |||
| 1 214 | 1 052 304 | 0.579001 | |||
| 1 160 452 | 0.638506 | ||||
| 1 240 985 | 0.682817 | ||||
| 1 242 019 | 0.683386 | ||||
| 1 307 201 | 0.719250 | ||||
| 1 377 359 | 0.757853 | ||||
| 1 467 679 | 1 361 | 0.807549 | |||
| 1 608 826 | 3 214 | 0.885211 | |||
| 1 635 882 | 3 967 | 0.900098 | |||
| 1 695 851 | 7 643 | 0.933094 | |||
| 1 699 685 | 8 069 | 0.935204 | |||
| 1 705 221 | 8 761 | 0.938250 | |||
| 1 709 988 | 9 442 | 0.940873 | |||
| 1 354 | 1 718 112 | 10 796 | 0.945343 | ||
| 1 971 | 1 727 967 | 12 767 | 0.950765 | ||
| 3 306 | 1 741 191 | 16 073 | 0.958041 | ||
| 5 053 | 1 756 350 | 21 126 | 0.966382 | ||
| 13 653 | 1 783 656 | 34 779 | 0.981406 | ||
| 33 793 | 1 817 449 | 68 572 | 1.000000 |
Из анализа содержания таблицы следует, что количество рангов частот наименований понятий используемых в исследовании документов составляет 836, а общее число наименований понятий в таких документах включает 1 817 449, из которых число разных понятий – всего 68 572. При этом наименования понятий в таких документах распределены неравномерно. Так, упоминание слова «проверка» имеет максимальную частоту 55 255, в то же время более 32 тысяч слов и словосочетаний имеют частоту 1.
Для создания АСС предлагается использовать полученный в результате исследования частный частотный словарь наименований понятий, исключив из его состава высокочастотную и малочастотную части.
В процессе исследований было эмпирически установлено, что пороговым критерием для исключения выcокочастотной лексики является значение частоты равное:
 , (5)
, (5)
где  – высокочастотное пороговое значение;
– высокочастотное пороговое значение;
– число документов в коллекции.
Этому значению частоты в наибольшей степени соответствует ранг частоты 
со значением 300 (325 понятий с покрытием понятий отобранных документов на 63,8%).
При формировании низкочастотного порогового значения ранга частоты, определяющего число исключенных из состава частотного словаря малочастотных понятий, необходимо исходить из значения минимального объема кластера.
Если принять, что минимальными объемом кластера может быть кластер
с объемом не менее 10 документов, тогда нижнее пороговое значения частот принимает равной 10.
 , (6)
, (6)
где  – верхнее пороговое значение;
– верхнее пороговое значение;
 – минимальное число документов в кластере (этому критерию в данном случае будет соответствовать количество разных понятий равное 7 643 с покрытием понятий отобранных документов рангом частот более 10 на 93,3%).
– минимальное число документов в кластере (этому критерию в данном случае будет соответствовать количество разных понятий равное 7 643 с покрытием понятий отобранных документов рангом частот более 10 на 93,3%).
В этом случае объем АСС будет равен:
 . (7)
. (7)
Покрытие отобранных документов понятиями АСС будет равно 30% (93,3 %.-
63,8 % = 29,5%).
Такое значение покрытия АСС соответствует эмпирически установленному оптимальному значению покрытия для автоматически создаваемых АСС, предназначенных для различных текстов. Всем элементам словаря назначались весовые коэффициенты по формулам (3 и 4).
Проведенные эксперименты показали недостаточную смыслоразличающую способность АСС, обусловленную тем фактом, что семантически значимые для заданной тематики однословные понятия и аббревиатуры имеют неприемлемо низкий весовой коэффициент. Поэтому было решено увеличить вес смысловой значимости тех однословным понятиям, которые входят в состав разработанного в процессе данного исследования тематического концептуального словаря (далее – ТКС) и переназначить
в словаре АСС их весовые коэффициенты. Для этого понятия, которые были идентифицированы с элементами словаря, включены в состав АСС и им присваивались новые весовые коэффициенты смысловой значимости в соответствии с формулой (8).
 , (8)
, (8)
где  – частота;
– частота;
 – число слов в словосочетании;
– число слов в словосочетании;
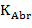 – в словаре ТКС определено как аббревиатура;
– в словаре ТКС определено как аббревиатура;
 – в словаре ТКС определено как значимое понятие предметной области.
– в словаре ТКС определено как значимое понятие предметной области.
Эксперименты, проведенные с модифицированным АСС с повышенными весовыми коэффициентами значимых понятий, показали его эффективность путем существенного повышения роли тех понятий, которые в наибольшей степени определяют основное смысловое содержание документов.
На втором этапе по текстам каждого из отобранных документов был автоматически сформирован понятийный образ документа (ПОД). Формирование ПОД осуществлялось путем выявления и идентификации в документе понятий, являющихся элементами АСС. При этом процесс идентификации понятий производился на уровне словоизменительной нормализации слов, входящих в состав понятий.
Для каждого ПОД вычислялась его семантическая характеристика[2], которая использовалась при формировании первоначального списка кластерообразующих отобранных документов. В список кластерообразующих документов включались документы, семантическая характеристика которых превышала пороговое значение.
На третьем этапе выполнялся процесс автоматического формирования кластеров отобранных документов. Формирование каждого кластера производилось путем сопоставления элементов ПОД кластерообразующего документа с ПОД всех отобранных документов. В процессе такого сопоставления ПОД вычислялось как отношение суммы весов совпавших элементов ПОД с весом ПОД кластерообразующего документа. При этом в зависимости от заданного порогового значения этого отношения принималось решение о включение документа в кластер данного кластерообразующего документа.
Для существенного уменьшения числа сравнений ПОД отобранных документов
в процессе кластеризации было принято следующее допущение: если процент совпадения весов ПОД кластероообразующего документа и сравниваемого документа выше порогового (например, выше 30%), то эти документы являются семантически близкими
и в дальнейшем этот сравниваемый документ не должен использоваться в качестве кластероообразующего.
В рамках этих допущений было решено организовать два списка документов, изменяющихся в процессе кластеризации. Первый список («черный») должен включать документы, которые будут использовать в качестве кластерообразующих. Первоначально он сформирован на основе использования семантических характеристик ПОД.
В процессе кластеризации (формирования кластеров) из него должны исключаться
те документы, которые уже использовались в качестве кластерообразующих,
и те документы, которые попали хотя бы в один из сформированных кластеров. Признаком завершения процесса кластеризации будет отсутствие документов в «черном» списке.
Одновременно для контроля процесса кластеризации был создан постоянно пополняемый список («белый» список) документов, входящих хотя бы в один
из сформированных кластеров. По завершению процесса кластеризации количество документов «белого» списка должно быть равно количеству документов коллекции.
Завершающим этапом процесса кластеризации являются операции нахождение центроида для каждого кластера, формирования названия кластера, а также проверка истинности процесса кластеризации. В процессе такой проверки должно быть установлено, что в каждом из отобранных документов содержится обобщенное содержание кластера. Эту проверка осуществляется путем формирования дайджеста кратких рефератов документов кластера. Все эти операции базируются на использовании автоматически создаваемого концептуального словаря кластера (далее – КСК). Этот словарь строится для каждого кластера на основе анализа содержания документов, входящих в данный кластер.
Поиск центроида осуществляется путем «взвешивания» вновь построенных ПОД по КСК и должен удовлетворять двум условиям:
а) ПОД должен иметь максимальный вес;
б) источник документа должен быть включен в список верифицированных источников.
4. Реализация процесса технологического процесса кластеризации
На основе предложенных решений разработан обобщенный технологический порядок процесса кластеризации, приведенная в таблице 2.
Таблица 2
Обобщенный технологический порядок процесса кластеризации
| № п/п | Содержание |
Этап 1. Конвертирование и формально-логический контроль каждого из отобранных документов
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|