- Автоматизация
- Антропология
- Археология
- Архитектура
- Биология
- Ботаника
- Бухгалтерия
- Военная наука
- Генетика
- География
- Геология
- Демография
- Деревообработка
- Журналистика
- Зоология
- Изобретательство
- Информатика
- Искусство
- История
- Кинематография
- Компьютеризация
- Косметика
- Кулинария
- Культура
- Лексикология
- Лингвистика
- Литература
- Логика
- Маркетинг
- Математика
- Материаловедение
- Медицина
- Менеджмент
- Металлургия
- Метрология
- Механика
- Музыка
- Науковедение
- Образование
- Охрана Труда
- Педагогика
- Полиграфия
- Политология
- Право
- Предпринимательство
- Приборостроение
- Программирование
- Производство
- Промышленность
- Психология
- Радиосвязь
- Религия
- Риторика
- Социология
- Спорт
- Стандартизация
- Статистика
- Строительство
- Технологии
- Торговля
- Транспорт
- Фармакология
- Физика
- Физиология
- Философия
- Финансы
- Химия
- Хозяйство
- Черчение
- Экология
- Экономика
- Электроника
- Электротехника
- Энергетика
Организация хранения и доступа к данным
Организация хранения и доступа к данным
В физической БД следует рассматривать методы размещения (запись и хранение) данных и методы доступа (поиск) к ним.
Основными методами хранения и поиска являются физически последовательный, прямой, индексно-последовательный и индексно-произвольный. Для их сравнительной оценки используем два критерия: Эффективность хранения - величина, обратная среднему числу байтов вторичной памяти, необходимому для хранения одного байта исходной памяти.
Эффективность доступа - величина, обратная среднему числу физических обращений, необходимых для осуществления логического доступа.
Выделяют первичные (физически последовательный и произвольный) и вторичные (мультисписковый, инвертированный файлы, двусвязное дерево) методы доступа.
Дадим этим методам краткую характеристику.
Физически последовательный метод. Записи хранятся в логической последовательности, файл имеет постоянный размер, указатели могут отсутствовать. Данные хранятся в главном файле, а обновление требует создания нового главного файла с упорядочением, для чего используется вспомогательный файл. Эффективность использования памяти близка к ста процентам, эффективность доступа низка.
Метод удобен для режима 1, однако быстродействие в режиме 2 мало: для его повышения необходимо использовать бинарный поиск (B- и B+-деревья). Время включения и удаления записей значительно.
Разновидностью метода является физически связанный (связанно-последовательный) метод, который называют также плотным. Имеются несмежные физические участки данных, используются указатели. Осуществляется динамическое перераспределение памяти: в одной и той же области памяти может выполняться несколько процессов или работают с данными, обладающими большой изменчивостью. При включении и удалении данных меняется только логика поиска. В режиме 1 время поиска мало, в режиме 2 - большое. Затраты на вторичную память малы. Применять бинарный поиск здесь нельзя из-за неплотной упаковки файлов и невозможности вычислять адреса.
В организации данных используется целая группа индексных методов, основными из которых являются индексно-последовательный и индексно-произвольный методы.
Индексно-последовательный метод. Индексный файл упорядочен по первичному ключу (главному атрибуту физической записи). Индекс содержит ссылки не на каждую запись, а на группу записей (рис. 9.2). Последовательная организация индексного файла допускает, в свою очередь, его индексацию - многоуровневая индексация (рис. 9.3).
Процедура добавления возможна в двух видах.
- Новая запись запоминается в отдельном файле (области), называемом областью переполнения. Блок этой области связывается в цепочку с блоком, которому логически принадлежит запись. Запись вводится в основной файл.
- Если места в блоке основного файла нет, запись делится пополам и в индексном файле создается новый блок.
Наличие индексного файла большого размера снижает эффективность доступа. В большой БД основным параметром становится скорость выборки первичных и вторичных ключей. При большой интенсивности обновления данных следует периодически проводить реорганизацию БД. Эффективность хранения зависит от размера и изменяемости БД, а эффективность доступа - от числа уровней индексации, распределения памяти для хранения индекса, числа записей в БД, уровня переполнения.
При произвольных методах записи физически располагаются произвольно.
Индексно-произвольный метод. Записи хранятся в произвольном порядке. Создается отдельный файл, хранящий значение действительного ключа и физического адреса (индекса). Каждой записи соответствует индекс. Общая схема показана на рис. 9.4.
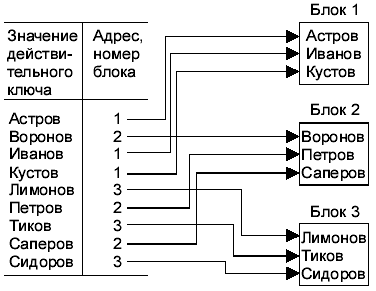
Идея метода отражена на рис. 9.5: между вырабатываемым (относительным) адресом и физической записью (абсолютным адресом) существует взаимнооднозначное соответствие.
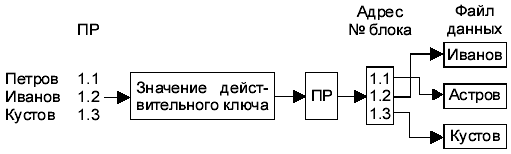
Разновидностью этого метода является наличие плотного индекса: кроме главного файла создается вспомогательный, называемый плотным индексом. Он состоит из записи (v, p) для любого значения ключа v в главном файле, где p - указатель на запись главного файла со значением ключа v.
Прямой метод. Имеется взаимнооднозначное соответствие между ключом записи и ее физическим адресом (рис. 9.6).
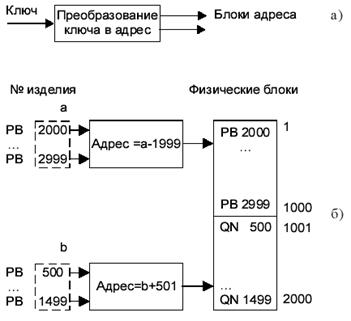
Выделяют два вида адресов (рис. 9.7) относительный и абсолютный:
В этом методе необходимо преобразование и надо четко знать исходные данные и организацию памяти. Ключи должны быть уникальными.
Эффективность доступа равна 1, а эффективность хранения зависит от плотности ключей.
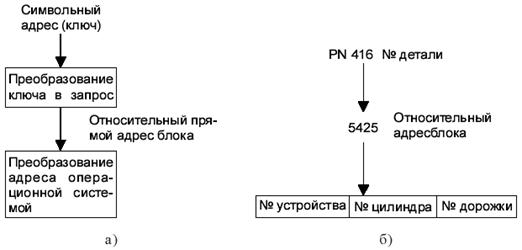
Если не требовать взаимнооднозначности, то получается разновидность метода с использованием хеширования - быстрого поиска данных, особенно при добавлении элементов непредсказуемым образом.
Хеширование - метод доступа, обеспечивающий прямую адресацию данных путем преобразования значений ключа в относительный или абсолютный физический адрес.
Адрес является функцией значения поля и ключа записи. Записи, приобретающие один адрес, называются синонимами. В качестве критериев оптимизации алгоритма хеширования могут быть: потеря связи между адресом и значением поля, минимум синонимов. Память делится на страницы определенного размера, и все синонимы помещаются в пределах одной страницы или в область переполнения. Механизм поиска синонимов - цепочечный.
Любой элемент хеш-таблицы имеет особый ключ, а само занесение осуществляется с помощью хеш-функции, отображающей ключи на множество целых чисел, которые лежат внутри диапазона адресов таблицы.
Хеш-функция должна обеспечивать равномерное распределение ключей по адресам таблицы, однако двум разным ключам может соответствовать один адрес. Если адрес уже занят, возникает состояние, называемое коллизией, которое устраняется специальными алгоритмами: проверка идет к следующей ячейке до обнаружения своей ячейки. Элемент с ключом помещается в эту ячейку.
Для поиска используется аналогичный алгоритм: вычисляется значение хеш-функции, соответствующее ключу, проверяется элемент таблицы, находящийся по указанному адресу. Если обнаруживается пустая ячейка, то элемента нет.
Размер хеш-таблицы должен быть больше числа размещаемых элементов. Если таблица заполняется на шестьдесят процентов, то, как показывает практика, для размещения нового элемента проверяется в среднем не более двух ячеек. После удаления элемента пространство памяти, как правило, не может быть использовано повторно.
Простейшим алгоритмом хеширования может являться функция f(k)єk (mod 10), где k - ключ, целое число (табл. 9.1)
Таблица 9.1.
|
|
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна.
|