Результат сортировки. Рис. 3.1. Пример сортировки вставками. Метод бинарных (двоичных) включений. Сортировка методом Шелла. Рис. 3.2. Пример сортировки методом Шелла. Обменная сортировка. Метод прямого обмена (пузырьковая сортировка). Результат сортировки
Сортировка методом Шелла представляет собой модификацию метода простых вставок. Повышение эффективности метода достигается за счет дополнительной возможности обмена местами элементов, расположенных на отдаленных позициях. Суть метода заключается в следующем: на каждой итерации сравниваются и сортируется между собой элементы, расположенные на некотором расстоянии d друг от друга. На каждой последующей итерации значение d уменьшается. На последнем шаге , что соответствует методу обычной сортировки вставками.
Одним из важных моментов сортировки является выбор начального и промежуточных значений параметра d. Существует множество подходов к их определению. Автором метода, изобретателем Дональдом Шеллом, предложена следующая последовательность длин расстояний:
(3.1)
Здесь значение первого расстояния определяется как половина числа элементов исходного массива; на каждой последующей итерации это расстояние делится пополам, пока не будет постигнуто значение 1. В худшем случае сложность алгоритма составит .
Альтернативный вариант предложен Хиббардом. Здесь расстояние d на каждой итерации определяется в виде последовательности чисел, определяемых по формуле , . Такая последовательность приводит к сложности .
Пример сортировки массива ( ) методом Шелла приведен на рисунке 3.2. Расстояния d рассчитаны согласно выражению (3.1) и представляют собой последовательность .
Итерация i
Результат сортировки
3
83
10
38
61
83
Итог:
Рис. 3.2. Пример сортировки методом Шелла
На рисунке одним цветом выделены элементы, сортируемые в рамках одной итерации. На первой итерации сортируются подсписки, состоящие из 2 элементов: , , , . На второй итерации сортируются списки и . На последней, третьей итерации, методом простых вставок сортируется весь массив .
Принято считать, что в определенных случаях при сортировке методом Шелла элементы быстрее «встают на свои места», чем в более простых методах сортировки.
3.3. Обменная сортировка
Эта группа методов сортировки подразумевает систематический обмен местами пар элементов, для которых имеется нарушение их упорядоченности. Сортировка прекращается тогда, когда таких пар элементов не остается в последовательности.
Метод прямого обмена (пузырьковая сортировка)
Метод основывается на сравнении и последующем перестановке пары соседних элементов в местах, где нарушен порядок сортировки. На первом шаге сравниваются ключи и . Если порядок их сортировки нарушен, элементы и меняются местами. На следующем шаге проверяются элементамы и и т. д. При последовательном повторении операции запись с самым большим значением ключа будет передвигаться вправо, пока не займет положение . При многократном повторении процесса будут заполняться позиции , и т. д. Действие выполняется до тех пор, пока вся последовательность не будет окончательно отсортирована. Очевидно, что часть массива, где элементы заняли свои окончательные позиции, могут не рассматриваться на следующих итерациях.
Пример сортировки пузырьковым методом массива ( ) приведен на рисунке 3.3. Здесь первая итерация рассмотрено подробно, с указанием всех перемещений, которые происходят на каждом шаге итерации. Для остальных итераций приведен лишь конечный результат.
Итерация i
Результат сортировки
40
6161
861
3861
112112
10112
3112
83
Итог:
Рис. 3.3. Пример сортировки пузырьковым методом
___ – текущие проверяемые элементы;
– операция взаимного обмена элементов;
– элемент, занявший окончательную позицию в отсортированной последовательности
На 6-й итерации не произошло ни одного обмена, следовательно, массив был полностью отсортирован.
Сортировка получила свое название, по подобию с процессом всплытия пузырька воздуха в воде. Если последовательность расположить не горизонтально, а вертикально, на каждой итерации максимальный элемент неотсортированной последовательности (самый «большой пузырек») будет «всплывает» наверх, занимая свою конечную позицию.
Достоинством пузырьковой сортировки является простота ее программной реализации. Однако вопрос о том, какой метод сортировки реализуется проще – метод вставок, метод прямого выбора или пузырьковый – не имеет однозначного ответа. В общем случае быстродействие пузырькового метода не превосходит другие рассмотренные.
Метод пузырьковой сортировки хорошо работает на практически отсортированных массивах за счет снижения числа перестановок. Метод позволяет легко определить момент полной упорядоченности массива проверкой отсутствия перестановок на итерации и исключить последние «пустые» итерации сортировки.
Шейкерная сортировка (сортировка перемешиванием)
Шейкерная сортировка реализует на каждой итерации пузырьковую сортировку, меняя каждый раз при этом направление просмотра.
Пример шейкерной сортировки массива ( ) приведен на рисунке 3.4. Подробно шаги первой итерации рассмотрены на рисунке 3.3.
Итерация i
Результат сортировки
40
Итог:
Рис. 3.4. Пример сортировки шейкерным методом
– перемещение элемента;
– элемент, занявший окончательную позицию в отсортированной последовательности
Применение шейкерного метода позволило выполнить сортировку за 5 итераций: на итерации 5 не произошло ни одного обмена и сортировка была прекращена.
Быстрая сортировка
3.4. Сортировка выбором
Это семейство методов сортировки основано реализует идею многократного выбора и замены элементов между собой. Методы требуют наличия всех исходных элементов до начала сортировки.
Сортировка методом прямого выбора
Сортировка выбором – один из самых простых методов сортировки. Его суть заключается в следующем: в массиве отыскивается элемент с наименьшим ключом и меняется местами с первым элементом массива . На следующей итерации находится второй наименьший элемент и меняется со вторым элементом массива . Итерации обмена продолжаются до тех пор, пока весь массив не будет отсортирован (всего потребуется выполнить итераций). Время сортировки выбором пропорционально .
Пример сортировки выбором массива ( ) приведен на рисунке 3.5.
Итерация i
Результат сортировки
40
61
61
112
112
Итог:
Рис. 3.5. Пример сортировки выбором
– минимальный элемент в диапазоне поиска;
– заменяемый на i-й итерации элемент;
| – левая граница сортировки
К недостаткам метода можно отнести то, что время сортировки не зависит от упорядоченности исходного файла – практически отсортированный файл и файл с случайной последовательностью элементов будут сортироваться приблизительно одинаковое время. Главным превосходство метода над другими является минимальное число перемещений при сортировке. Этому методу отдают предпочтение при сортировке данных большого размера – в этом случае затраты ресурсов на перезапись данных существенно превосходят затраты на сравнение ключей.
3.5. Сортировка слиянием
Под слиянием понимается двух и более упорядоченных массивов в единый упорядоченный массив.
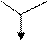
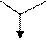
Один из самых простых способов слияния – последовательное сравнение наименьших элементов массива с целью определения наименьшего из них. Найденный элемент выводится (или заносится в дополнительный массив), и процедура повторяется с оставшимися в массивах элементами. Пример слияния двух упорядоченных массивов ) и ( приведен на рисунке 3.6.
Результат слияния:
Сливаемые массивы:
Рис. 3.6. Пример слияния двух массивов
– минимальный элемент
Сортировка методом простого слияния
Суть метода заключается в следующем: сортируемый массив разбивается на подмассивы таким образом, что в каждом подмассиве содержится один элемент исходного массива, число подмассивов – . Полученные подмассивы попарно сливаются на каждой следующей итерации до тех пор, пока не будет получен один отсортированный массив размерностью .
Пример сортировки методом простого слияния массива ( ) приведен на рисунке 3.7.
[40] [61] [8] [38] [112] [10] [3] [83]
[40 61] [8 38] [10 112] [3 83]
[8 38 40 61] [3 10 83 112]
[3 8 10 38 40 61 83 112]
Рис. 3.7. Пример сортировки методом простого слияния
Метод простого слияния считается одним из самых простых среди быстрых методов сортировки. Вычислительная сложность алгоритма оценивается как .
3.6. Поразрядная сортировка
Поразрядными методами сортировки называются методы, построенные на обработке чисел по одной позиции (одному разряду) за итерацию. Эти методы обрабатывают и сравнивают не весь ключ целиком, а его часть. Отличительной особенностью данной группы методов является то, что они не используют сравнений ключей.
Приято выделять два базовых подхода к поразрядной сортировке. В первом случае ключи рассматриваются слева направо (от старших разрядов к младшим), во втором – справа налево (от старших разрядов к младшим). Первая группа методов получила название MSD (most significant digit radix sort – поразрядная сортировка по старшей цифре), вторая – LDS (least significant digit radix sort – поразрядная сортировка по младшей цифре). При MSD-сортировке получается алфавитный порядок следования ключей (например, c, cd, fa, g, gr, ...), при сортировке чисел разной разрядности, они не будут отсортированы в порядке их фактических значений (например, 1, 10, 4, 51, 6, …). Сортировка LSD дает иной порядок следования ключей: короткие ключи идут раньше длинных, в пределах одной разрядности ключи сортируются по алфавиту. Такое представление совпадает с представлением числового ряда в порядке возрастания значений чисел: 1, 4, 6, 10, 51, … . В отличие от LSD сортировки, MSD-сортировка является устойчивой.
– количество возможных значений каждого разряда ключа.
MSD и LSD сортировки
Первым шагом методов поразрядной сортировки является разбиение ключа на разряды (для слов – это буквы, для чисел – цифры).
Пример сортировки массива ( ) методами MSD (a) и LSD (б) приведен на рисунке 3.8.
Для рассматриваемого примера , .
Исходная последовательность
Результат итерации 1
Результат итерации 2
Результат итерации 3
4 0
4 0
3
3
6 1
1 0
8
8
6 1
10
10
3 8
1 1 2
1 12
38
1 1 2
3
38
40
1 0
8 3
40
61
8
61
83
8 3
3 8
83
112
а) LSD-сортировка
ГЛАВА 4. ПОИСК
Как и в случае с сортировкой, методы поиска предполагают работу с данными, разделенными на записи (элементы), каждая из которых имеет уникальную характеристику – ключ. Цель поиска – получение элемента с ключом, соответствующем заданному ключу поиска.
Значимость операции поиска сложно переоценить. Она привлекала большое внимание специалистов-информатиков еще на заре компьютерной техники. В ту пору многие математические вычисления сводились к процедуре поиска (отыскание нужных значений в таблицах логарифмов, тригонометрических и иных таблицах). Широкое внедрение вычислительных машин в процесс решения научных задач в некоторых случаях заменили поиск на многократное повторное вычисление одних и тех же значений функций. Однако в некоторых случаях оказалось выгоднее не отказываться от поиска данных по таблицам.
Основная проблема, с которой сталкивались ученые при разработке методов поиска, заключалась в ограниченном доступе к данным (например, при хранении информации на лентах был возможен только последовательный однонаправленный доступ). В таких условиях эффективный поиск был невозможен. Разработка новых видов устройств памяти с произвольным доступом в 50-х года прошлого века привела к прорыву в области разработки методов поиска. Исследования в данной области не потеряли свою актуальность и в настоящее время.
Сегодня операция поиска в той или иной степени используется практически во всех программах. При этом данная процедура считается наиболее времязатратной ее частью. В связи с этим, разработка эффективных методов поиска позволяет существенно увеличить скорость работы таких программ.
Аналогично методам сортировки, методы поиска можно разделить на внутренние (когда данные хранятся в оперативной памяти) и внешние (данные располагаются на внешних носителях).
По принципу действия методы поиска могут быть разделены на две группы:
· методы, основанные на сравнении ключей (последовательный, бинарный, интерполяционный, по бинарному дереву и пр.);
· методы, основанные на цифровых свойствах ключей.
К первой группе метод
4.1. Постановка задачи поиска
Пусть имеется последовательность из элементов
.
Каждой записи последовательности поставлен в соответствие ключ .
Наряду с ключом, элементу может соответствовать иная информация, не влияющая на процесс поиска.
Ставится задача: отыскать в множестве элемент , ключ которого совпадает с ключом поиска .
Процедура поиска может быть завершена в двух случаях:
· ключ найден;
· проверены все элементы множества и элемент с ключом отсутствует во множестве.
4.2. Методы поиска, основанные на сравнении ключей
Последовательный поиск
Последовательный (или другими словами линейный) поиск является одним из самых очевидных и понятных методов отыскания данных в массиве. Суть метода можно описать так: начать поиск с первого элемента массива, последовательно проверять элементы до тех пор, пока не будет найден искомый ключ.
Достоинством метода является отсутствие необходимости предварительной сортировки данных.
Несмотря на всю очевидность и однозначность, последовательный поиск имеет так называемую быструю реализацию, которая на данных большой размерности позволяет в разы сократить время поиска.
В среднем линейный поиск требует сравнений, в худшем случае число сравнений может достигать . Для массивов большой размерности время последовательного поиска велико, в связи с чем его редко применяют на практике.
Бинарный поиск
Бинарный поиск требует предварительной сортировки данных в порядке возрастания ключей
На первом шаге ключ сравнивается с центральным элементом множества. Номер центрального элемент определяется по формуле:
.
– целая часть от деления .
Если:
· – искомый элемент найден;
· – поиск продолжается в правой половине подмассива ( );
· – поиск продолжается в левой половине подмассива ( ).
Пример 4.1:Задано упорядоченное множество, состоящее из элементов c ключами
Требуется найти в множестве элемент с ключом .
Найдем индекс центрального элемента: .
Ключ центрального элемента , что меньше ключа поиска :
.
Следовательно, дальнейший поиск следует производить в подмассиве, расположенном справа от центрального элемента ( ).
Для нового подмассива . Найдем индекс центрального элемента: .
Ключ центрального элемента , что больше ключа поиска :
.
Это означает, что следующий подмассив будет располагаться левее текущего центрального элемента.
На итерации 3 центральный элемент совпадает с ключом поиска, поэтому алгоритм завершает работу.
Иллюстрация шагов бинарного поиска приведена на рисунке 4.1.
Итерация 1:
Итерация 2:
Итерация 3:
Рис. 4.1. Пример бинарного поиска
- центральный элемент массива;
- диапазон поиска на текущей итерации
В наихудшем случае бинарный поиск требует сравнений. Уже при бинарный поиск в разы превзойдет линейный по времени выполнения.
Интерполяционный поиск
Это – метод поиска в отсортированном массиве в основу которого положена операция интерполяции. По принципу действия интерполяционный поиск схож с бинарным: в нем также выделяется некоторая подобласть поиска, которая сужается на каждой последующей итерации. Но в отличии от бинарного, интерполяционный поиск не делит массив на две равные части. На каждой итерации делается попытка рассчитать приблизительное расположение ключа в массиве.
Если проводить аналогию с поиском в реальной жизни, то интерполяционный поиск можно сравнить с поиском в телефонном справочнике – если нужно найти абонента с фамилией на букву «В» или «Г», то разумно начинать поиск в начале справочника, а не с середины или конца.
Центральный элемент в интерполяционном методе ищется по следующей формуле:
Здесь , – номера левого и правого элементов границ диапазона поиска; означают целую часть от операции деления.
Пример 4.2:Задано упорядоченное множество, состоящее из элементов c ключами
Требуется найти в множестве элемент с ключом .
Найдем индекс центрального элемента:
Ключ центрального элемента , что меньше ключа поиска :
.
Следовательно, дальнейший поиск следует производить в подмассиве, расположенном справа от центрального элемента ( ).
Найдем индекс центрального элемента:
На итерации 2 центральный элемент совпадает с ключом поиска, поэтому алгоритм завершает работу.
Иллюстрация шагов интерполяционного поиска приведена на рисунке 4.2.
Итерация 1:
Итерация 2:
Рис. 4.1. Пример интерполяционного поиска
- центральный элемент массива;
- диапазон поиска на текущей итерации
Интерполяционный поиск показывает хорошие результаты на массивах где данные распределены равномерно. Доказано, что интерполяционный поиск реализует менее, чем сравнений. Эта функция характеризуется очень медленными темпами роста, поэтому ее можно считать постоянной. Так, при , значение . Для небольших значений , функция по своим значениям близка к значениям функции , поэтому реализация интерполяционного поиска в массивах небольшой размерности неоправдана. Зачастую интерполяционный поиск используется на первых шагах операции поиска в массивах большой размерности, а последующие шаги выполняются бинарным или линейным поиском.
4.3. Хеширование
Хеширование (hashing - перемешивание) – расширенный вариант поиска с использованием индексирования по ключу. При таком поиске значения ключей используются в качестве индексов масс
 40
40
 40
40
 40
40
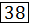
 61
61
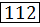
 8
8
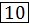
 8
8
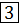
 61
61
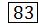
 – текущий проверяемый элемент;
– текущий проверяемый элемент; – место вставки элемента;
– место вставки элемента;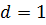 , что соответствует методу обычной сортировки вставками.
, что соответствует методу обычной сортировки вставками.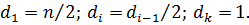 (3.1)
(3.1)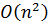 .
.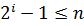 ,
, 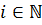 . Такая последовательность приводит к сложности
. Такая последовательность приводит к сложности 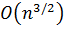 .
.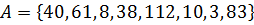 (
( 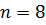 ) методом Шелла приведен на рисунке 3.2. Расстояния d рассчитаны согласно выражению (3.1) и представляют собой последовательность
) методом Шелла приведен на рисунке 3.2. Расстояния d рассчитаны согласно выражению (3.1) и представляют собой последовательность 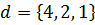 .
.




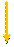 Результат сортировки
Результат сортировки



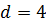




 3
3
 83
83








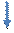
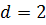
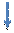 10
10
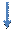 38
38
 61
61
 83
83







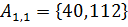 ,
, 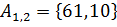 ,
, 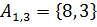 ,
, 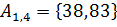 . На второй итерации сортируются списки
. На второй итерации сортируются списки 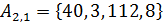 и
и 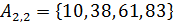 . На последней, третьей итерации, методом простых вставок сортируется весь массив
. На последней, третьей итерации, методом простых вставок сортируется весь массив 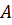 .
.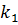 и
и 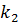 . Если порядок их сортировки нарушен, элементы
. Если порядок их сортировки нарушен, элементы 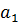 и
и 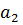 меняются местами. На следующем шаге проверяются элементамы
меняются местами. На следующем шаге проверяются элементамы 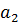 и
и 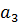 и т. д. При последовательном повторении операции запись с самым большим значением ключа будет передвигаться вправо, пока не займет положение
и т. д. При последовательном повторении операции запись с самым большим значением ключа будет передвигаться вправо, пока не займет положение 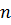 . При многократном повторении процесса будут заполняться позиции
. При многократном повторении процесса будут заполняться позиции 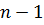 ,
, 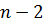 и т. д. Действие выполняется до тех пор, пока вся последовательность не будет окончательно отсортирована. Очевидно, что часть массива, где элементы заняли свои окончательные позиции, могут не рассматриваться на следующих итерациях.
и т. д. Действие выполняется до тех пор, пока вся последовательность не будет окончательно отсортирована. Очевидно, что часть массива, где элементы заняли свои окончательные позиции, могут не рассматриваться на следующих итерациях. 61
61

 61
61

 112
112
 112
112
 112
112
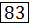
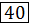
 – операция взаимного обмена элементов;
– операция взаимного обмена элементов;


 40
40


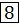
 – перемещение элемента;
– перемещение элемента;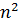 .
.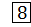
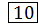
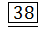
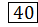
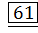
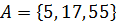
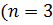 ) и
) и 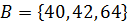 (
( 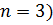 приведен на рисунке 3.6.
приведен на рисунке 3.6.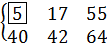
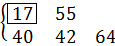
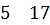
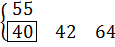
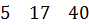
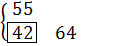
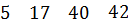

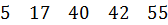

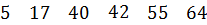

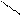
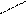

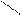
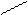
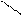

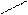
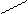

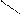
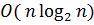 .
.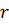 – количество разрядов самого длинного ключа;
– количество разрядов самого длинного ключа;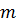 – количество возможных значений каждого разряда ключа.
– количество возможных значений каждого разряда ключа.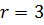 ,
, 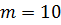 .
.


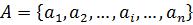 .
.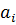 записи последовательности поставлен в соответствие ключ
записи последовательности поставлен в соответствие ключ 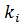 .
.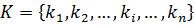
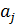 , ключ
, ключ 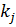 которого совпадает с ключом поиска
которого совпадает с ключом поиска 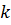 .
.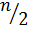 сравнений, в худшем случае число сравнений может достигать
сравнений, в худшем случае число сравнений может достигать 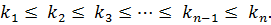
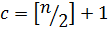 .
.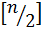 – целая часть от деления
– целая часть от деления 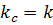 – искомый элемент найден;
– искомый элемент найден;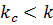 – поиск продолжается в правой половине подмассива (
– поиск продолжается в правой половине подмассива ( 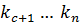 );
);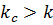 – поиск продолжается в левой половине подмассива (
– поиск продолжается в левой половине подмассива ( 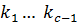 ).
).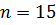 элементов c ключами
элементов c ключами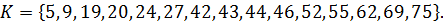
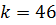 .
.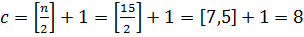 .
.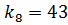 , что меньше ключа поиска
, что меньше ключа поиска 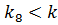 .
.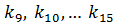 ).
).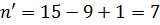 . Найдем индекс центрального элемента:
. Найдем индекс центрального элемента: 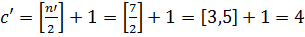 .
.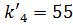 , что больше ключа поиска
, что больше ключа поиска 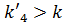 .
.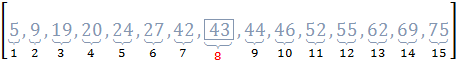
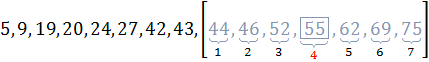
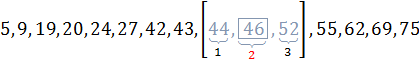
 - центральный элемент массива;
- центральный элемент массива; - диапазон поиска на текущей итерации
- диапазон поиска на текущей итерации сравнений. Уже при
сравнений. Уже при  бинарный поиск в разы превзойдет линейный по времени выполнения.
бинарный поиск в разы превзойдет линейный по времени выполнения.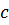 в интерполяционном методе ищется по следующей формуле:
в интерполяционном методе ищется по следующей формуле: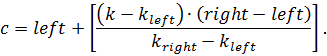
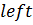 ,
, 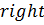 – номера левого и правого элементов границ диапазона поиска;
– номера левого и правого элементов границ диапазона поиска; 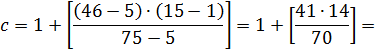
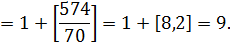
 , что меньше ключа поиска
, что меньше ключа поиска  .
.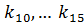 ).
).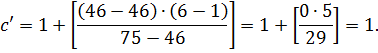
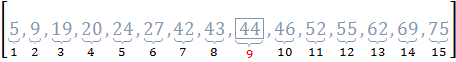
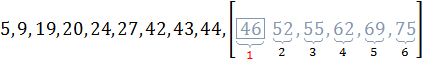
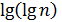 сравнений. Эта функция характеризуется очень медленными темпами роста, поэтому ее можно считать постоянной. Так, при
сравнений. Эта функция характеризуется очень медленными темпами роста, поэтому ее можно считать постоянной. Так, при 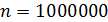 , значение
, значение 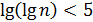 . Для небольших значений
. Для небольших значений 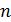 , функция
, функция 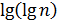 по своим значениям близка к значениям функции
по своим значениям близка к значениям функции 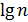 , поэтому реализация интерполяционного поиска в массивах небольшой размерности неоправдана. Зачастую интерполяционный поиск используется на первых шагах операции поиска в массивах большой размерности, а последующие шаги выполняются бинарным или линейным поиском.
, поэтому реализация интерполяционного поиска в массивах небольшой размерности неоправдана. Зачастую интерполяционный поиск используется на первых шагах операции поиска в массивах большой размерности, а последующие шаги выполняются бинарным или линейным поиском.